
Claude 的智能体 技能 (Skills) 系统代表了一种复杂的、基于提示词(prompt-based)的 元工具 (meta-tool) 架构,它通过专门的指令注入扩展了 大语言模型 (LLM) 的能力。与传统的函数调用或代码执行不同,skills 通过 提示词扩展 (prompt expansion) 和 上下文修改 (context modification) 来运作,从而在不编写可执行代码的情况下,改变 Claude 处理后续请求的方式。
本篇深度解析将从第一性原理(first principles)解构 Claude 的智能体技能系统,记录一个名为 “Skill” 的工具如何作为元工具将特定领域的提示词注入到对话上下文中。我们将以 skill-creator(技能创建者)和 internal-comms(内部通信)技能作为案例研究,以此贯穿整个生命周期,通过检查从文件解析、API 请求结构到 Claude 决策过程的每一个环节。
Claude 智能体技能概览 (Claude Agent Skills Overview)#
Claude 使用 技能 (Skills) 来改进其执行特定任务的方式。技能被定义为包含指令、脚本和资源的文件夹,Claude 可以在需要时加载它们。Claude 使用一种 声明式的、基于提示词的系统 来进行技能的发现和调用。AI 模型(Claude)根据系统提示词中呈现的文本描述来决定是否调用 skills。在代码层面不存在算法式的技能选择或 AI 驱动的意图检测。决策完全发生在 Claude 的推理过程中,依据的是所提供的技能描述。
Skills 不是可执行代码。它们不运行 Python 或 JavaScript,幕后也没有 HTTP 服务器或函数调用在发生。它们也不是硬编码在 Claude 的系统提示词中。Skills 存在于 API 请求结构的一个独立部分中。
那么它们是什么?Skills 是专门的提示词模板,用于将特定领域的指令注入到对话上下文中。当一个技能被调用时,它会同时修改 对话上下文 (conversation context)(通过注入指令提示词)和 执行上下文 (execution context)(通过更改工具权限并可能切换模型)。技能不是直接执行动作,而是扩展为详细的提示词,让 Claude 做好解决特定类型问题的准备。每个技能看起来都是 Claude 所见工具模式(tool schema)的一个动态补充。
当用户发送请求时,Claude 接收三样东西:用户消息、可用工具(Read, Write, Bash 等)以及 Skill 工具。Skill 工具的描述包含了一份格式化的列表,列出了所有可用技能及其 name(名称)、description(描述)和其他字段的组合。Claude 读取这个列表,利用其自然语言理解能力将你的意图与技能描述进行匹配。如果你说“帮我为日志创建一个技能”,Claude 会看到 internal-comms 技能的描述(“当用户想要使用公司喜欢的格式编写内部通信时”),识别出匹配项,并使用命令 "internal-comms" 调用 Skill 工具。
术语说明 (Terminology Note):
- Skill 工具 (Skill tool - 大写 S) = 管理所有技能的 元工具 (meta-tool)。它出现在 Claude 的
tools数组中,与 Read, Write, Bash 等并列。- 技能 (skills - 小写 s) = 像
skill-creator,internal-comms这样的个体技能。这些是Skill工具所加载的专门指令模板。
下图更直观地展示了 Claude 如何使用 skills:
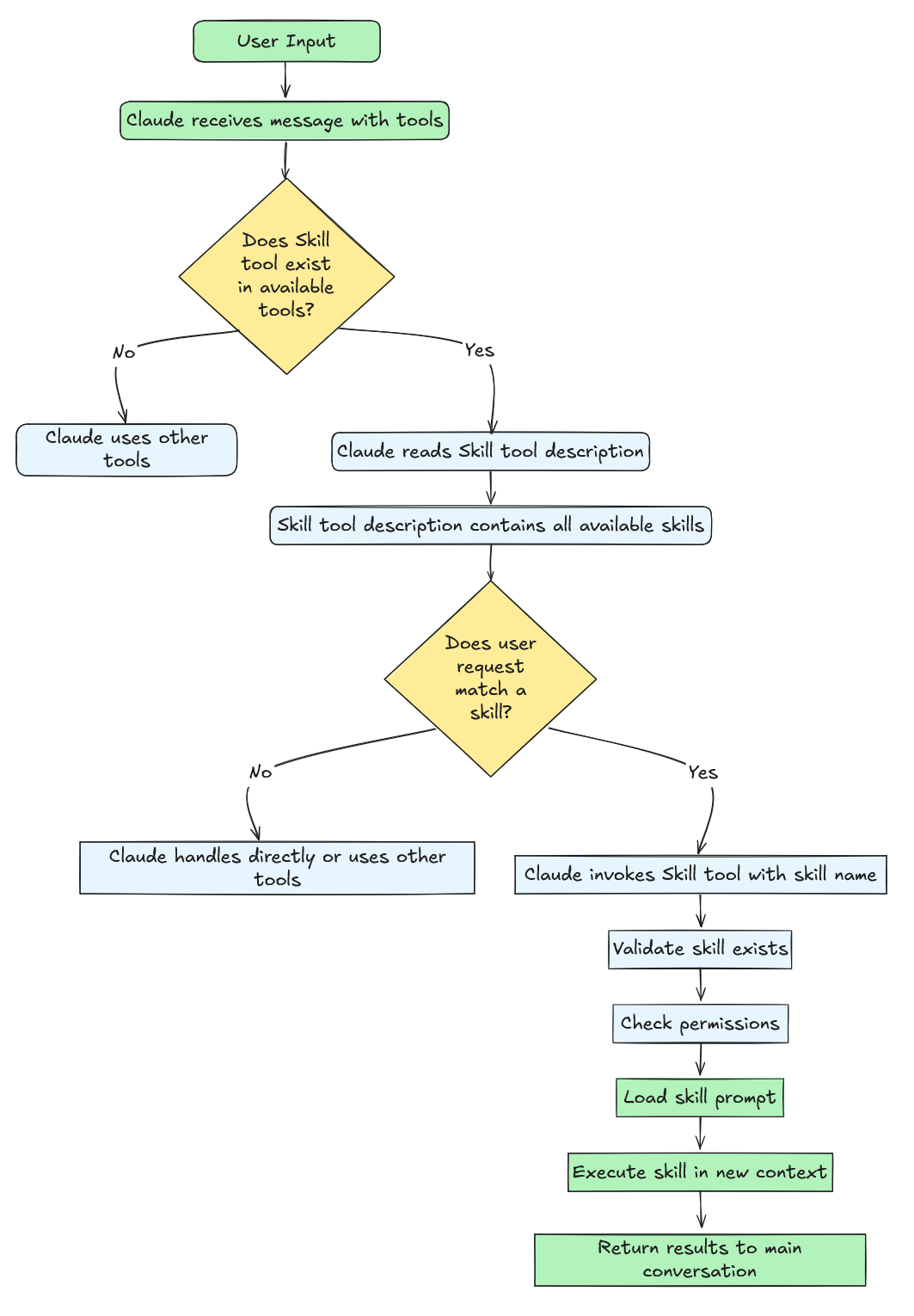
技能选择机制在代码层面没有算法路由或意图分类。Claude Code 不使用嵌入(embeddings)、分类器或模式匹配来决定调用哪个技能。相反,系统将所有可用技能格式化为嵌入在 Skill 工具提示词中的文本描述,并让 Claude 的语言模型做出决定。这是纯粹的 LLM 推理。没有正则表达式,没有关键词匹配,没有基于机器学习的意图检测。决策发生在 Claude 通过 Transformer 的前向传播(forward pass)内部,而不是在应用程序代码中。
当 Claude 调用一个技能时,系统遵循一个简单的工作流:它加载一个 markdown 文件 (SKILL.md),将其扩展为详细的指令,将这些指令作为新的用户消息注入到对话上下文中,修改执行上下文(允许的工具、模型选择),并在这种丰富后的环境中继续对话。这与传统工具根本不同,传统工具执行并返回结果。技能是 准备 (prepare) Claude 去解决一个问题,而不是直接解决它。
下表有助于更好地消除工具(Tools)和技能(Skills)及其能力之间的歧义:
| 方面 (Aspect) | 传统工具 (Traditional Tools) | 技能 (Skills) |
|---|---|---|
| 执行模型 | 同步,直接 | 提示词扩展 (Prompt expansion) |
| 目的 | 执行特定操作 | 引导复杂工作流 |
| 返回值 | 即时结果 | 对话上下文 + 执行上下文变更 |
| 示例 | Read, Write, Bash | internal-comms, skill-creator |
| 并发性 | 通常安全 | 非并发安全 |
| 类型 | 多种多样 | 始终是 “prompt” (提示词) |
构建智能体技能 (Building Agent Skills)#
现在让我们通过以 Anthropic 技能库中的 skill-creator 技能为例,深入探讨如何构建技能。提醒一下,智能体技能 (agent skills) 是由指令、脚本和资源组成的有组织的文件夹,智能体可以动态发现和加载它们,以便在特定任务上表现更好。Skills 通过将你的专业知识打包成 Claude 可组合的资源来扩展 Claude 的能力,将通用智能体转变为符合你需求的专用智能体。
核心洞察 (Key Insight): 技能 = 提示词模板 + 对话上下文注入 + 执行上下文修改 + 可选数据文件和 Python 脚本
每个 Skill 都定义在一个名为 SKILL.md(大小写不敏感)的 markdown 文件中,并带有存储在 /scripts、/references 和 /assets 下的可选打包文件。这些打包文件可以是 Python 脚本、Shell 脚本、字体定义、模板等。以 skill-creator 为例,它包含 SKILL.md、用于许可的 LICENSE.txt,以及 /scripts 文件夹下的一些 Python 脚本。skill-creator 没有任何 /references 或 /assets。
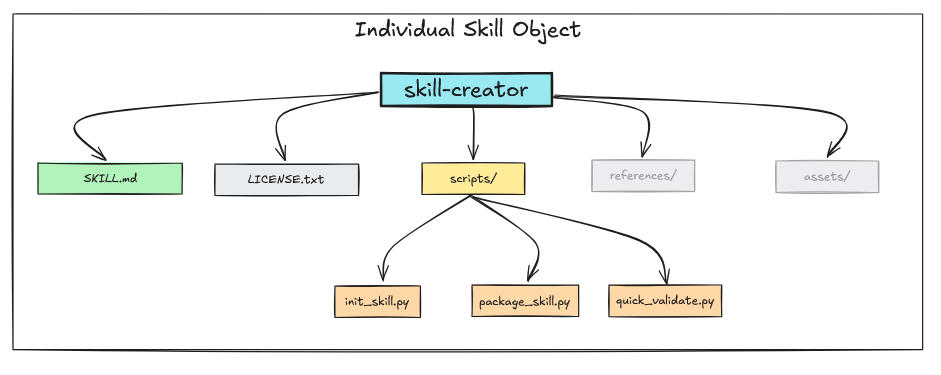
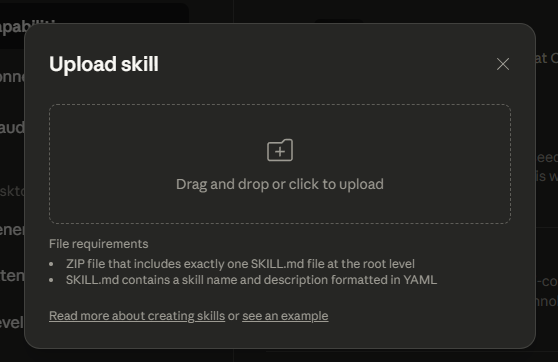
技能从多个来源被发现和加载。Claude Code 扫描用户设置 (~/.config/claude/skills/)、项目设置 (.claude/skills/)、插件提供的技能以及内置技能,以构建可用技能列表。对于 Claude Desktop,我们可以如下上传自定义技能。
注意: 构建技能最重要的概念是 渐进式披露 (Progressive Disclosure) —— 只展示足够的信息帮助智能体决定下一步做什么,然后在需要时展示更多细节。在 智能体技能 (agent skills) 的案例中:
- 披露 Frontmatter (前置元数据):极简信息(名称、描述、许可)。
- 如果选中某个
skill,加载SKILL.md:全面但聚焦的内容。- 然后在
skill执行时加载辅助资产、参考资料和脚本。
编写 SKILL.md (Writing SKILL.md)#
SKILL.md 是技能提示词的核心。它是一个 markdown 文件,遵循两部分结构——前置元数据(frontmatter)和内容。前置元数据配置技能 如何 (HOW) 运行(权限、模型、元数据),而 markdown 内容告诉 Claude 做什么 (WHAT)。前置元数据是用 YAML 编写的文件头。
┌─────────────────────────────────────┐
│ 1. YAML Frontmatter (Metadata) │ ← 配置 (Configuration)
│ --- │
│ name: skill-name │
│ description: Brief overview │
│ allowed-tools: "Bash, Read" │
│ version: 1.0.0 │
│ --- │
├─────────────────────────────────────┤
│ 2. Markdown Content (Instructions) │ ← 给 Claude 的提示词 (Prompt)
│ │
│ Purpose explanation │
│ Detailed instructions │
│ Examples and guidelines │
│ Step-by-step procedures │
└─────────────────────────────────────┘
Frontmatter (前置元数据)#
前置元数据包含控制 Claude 如何发现和使用技能的元数据。作为一个例子,这里是 skill-creator 的前置元数据:
---
name: skill-creator
description: Guide for creating effective skills. This skill should...
license: Complete terms in LICENSE.txt
---
让我们逐一浏览前置元数据的字段。

name (必填)#
不言自明。skill 的名称。skill 的 name 被用作 Skill Tool 中的 command(命令)。
description (必填)#
description 字段提供了技能功能的简要摘要。这是 Claude 用来确定何时调用技能的主要信号。在上面的例子中,描述明确指出“当用户想要创建一个新技能时应使用此技能”——这种清晰的、以行动为导向的语言有助于 Claude 将用户意图与技能能力相匹配。
系统会自动将来源信息附加到描述中(例如,"(plugin:skills)"),这有助于在加载多个技能时区分不同来源的技能。
when_to_use (未记录—可能已弃用或未来特性)#
⚠️ 重要提示:
when_to_use字段在代码库中广泛出现,但没有记录在任何官方 Anthropic 文档中。此字段可能是:
- 一个正在被逐步淘汰的弃用功能
- 一个尚未正式支持的内部/实验性功能
- 一个尚未发布的计划功能
建议: 依赖详细的
description字段代替。在官方文档出现之前,避免在生产环境的技能中使用when_to_use。
尽管未记录,但以下是 when_to_use 目前在代码库中的工作方式:
function formatSkill(skill) {
let description = skill.whenToUse
? `${skill.description} - ${skill.whenToUse}`
: skill.description;
return `"${skill.name}": ${description}`;
}
当存在时,when_to_use 会通过连字符分隔符附加到描述后面。例如:
"skill-creator": Create well-structured, reusable skills... - When user wants to...
这个组合字符串是 Claude 在 Skill 工具提示词中看到的内容。然而,由于此行为未记录,它可能会在未来的版本中更改或删除。更安全的方法是将使用指南直接包含在 description 字段中,如上面的 skill-creator 示例所示。
license (可选)#
不言自明。
allowed-tools (可选)#
allowed-tools 字段定义了技能可以在未经用户批准的情况下使用哪些工具,类似于 Claude 的 allowed-tools。
这是一个逗号分隔的字符串,会被解析为允许的工具名称数组。你可以使用通配符来限定权限范围,例如,Bash(git:*) 仅允许 git 子命令,而 Bash(npm:*) 允许所有 npm 操作。skill-creator 技能使用了 "Read,Write,Bash,Glob,Grep,Edit" 来赋予其广泛的文件和搜索能力。一个常见的错误是列出所有可用工具,这会产生安全风险并破坏安全模型。
只包含你的技能实际需要的工具——如果你只是读写文件,
"Read,Write"就足够了。
# ✅ skill-creator 允许使用多个工具
allowed-tools: "Read,Write,Bash,Glob,Grep,Edit"
# ✅ 仅限特定的 git 命令
allowed-tools: "Bash(git status:*),Bash(git diff:*),Bash(git log:*)"
# ✅ 仅限文件操作
allowed-tools: "Read,Write,Edit,Glob,Grep"
# ❌ 不必要的攻击面
allowed-tools: "Bash,Read,Write,Edit,Glob,Grep,WebSearch,Task,Ag..."
# ❌ 带有所有 npm 命令的不必要攻击面
allowed-tools: "Bash(npm:*),Read,Write"
model (可选)#
model 字段定义了技能可以使用哪个模型。默认情况下,它继承用户会话中的当前模型。对于像代码审查这样的复杂任务,技能可以请求更强大的模型,如 Claude Opus 或其他开源中文模型(懂得都懂)。
model: "claude-opus-4-20250514" # 使用特定模型
model: "inherit" # 使用会话的当前模型 (默认)
version, disable-model-invocation, 和 mode (可选)#
技能支持三个可选的前置元数据字段用于版本控制和调用控制。
version字段(例如version: "1.0.0")是一个元数据字段,用于跟踪技能版本,从前置元数据解析而来,但主要用于文档和技能管理目的。disable-model-invocation字段(布尔值)防止 Claude 通过Skill工具自动调用该技能。当设置为true时,该技能将从展示给 Claude 的列表中排除,只能由用户通过/skill-name手动调用,这使其非常适合需要显式用户控制的危险操作、配置命令或交互式工作流。mode字段(布尔值)将技能归类为“模式命令 (mode command)”,用于修改 Claude 的行为或上下文。当设置为true时,该技能会出现在技能列表顶部的特殊“模式命令”部分(与常规实用技能分开),使其对于像 debug-mode(调试模式)、expert-mode(专家模式)或 review-mode(审查模式)这样建立特定操作上下文或工作流的技能更加突出。
SKILL.md 提示词内容 (SKILL.md Prompt Content)#
在前置元数据之后是 markdown 内容——这是当 skill 被调用时 Claude 接收到的实际提示词。这是你定义 skill 的行为、指令和工作流的地方。编写有效技能提示词的关键是保持聚焦并使用 渐进式披露:在 SKILL.md 中提供核心指令,并引用外部文件以获取详细内容。
这是一个推荐的内容结构:
---
# Frontmatter here
---
# [Brief Purpose Statement - 1-2 sentences] (简短目的陈述)
## Overview (概述)
[What this skill does, when to use it, what it provides] (此技能做什么,何时使用,提供什么)
## Prerequisites (先决条件)
[Required tools, files, or context] (所需工具、文件或上下文)
## Instructions (指令)
### Step 1: [First Action] (步骤 1:首个动作)
[Imperative instructions] (命令式指令)
[Examples if needed] (如果需要,提供示例)
### Step 2: [Next Action] (步骤 2:下一个动作)
[Imperative instructions]
### Step 3: [Final Action] (步骤 3:最终动作)
[Imperative instructions]
## Output Format (输出格式)
[How to structure results] (如何构建结果)
## Error Handling (错误处理)
[What to do when things fail] (失败时做什么)
## Examples (示例)
[Concrete usage examples] (具体使用案例)
## Resources (资源)
[Reference scripts/, references/, assets/ if bundled] (引用的脚本、参考资料、资产)
作为一个例子,skill-creator 技能包含以下指令,指定了创建技能所需的每个工作流步骤。
## Skill Creation Process
### Step 1: Understanding the Skill with Concrete Examples
### Step 2: Planning the Reusable Skill Contents
### Step 3: Initializing the Skill
### Step 4: Edit the Skill
### Step 5: Packaging a Skill
当 Claude 调用此技能时,它会接收整个提示词作为新指令,并预先添加了基础目录路径。{baseDir} 变量解析为技能的安装目录,允许 Claude 使用 Read 工具加载参考文件:Read({baseDir}/scripts/init_skill.py)。这种模式保持了主提示词简洁,同时按需提供详细文档。
提示词内容的最佳实践:
- 保持在 5,000 字(约 800 行)以内,以避免压垮上下文。
- 使用命令式语言(“Analyze code for…”/“分析代码以…”),而不是第二人称(“You should analyze…”/“你应该分析…”)。
- 引用外部文件以获取详细内容,而不是嵌入所有内容。
- 使用
{baseDir}作为路径,绝不要硬编码绝对路径如/home/user/project/。
❌ Read /home/user/project/config.json
✅ Read {baseDir}/config.json
当技能被调用时,Claude 仅获得 allowed-tools 中指定的工具的访问权限,如果前置元数据中指定了模型,则模型可能会被覆盖。技能的基础目录路径会自动提供,使得打包的资源可被访问。
随技能打包资源 (Bundling Resources with Your Skill)#
当你将支持资源与 SKILL.md 一起打包时,Skills 会变得更加强大。标准结构使用三个目录,每个服务于特定目的:
my-skill/
├── SKILL.md # 核心提示词和指令
├── scripts/ # 可执行的 Python/Bash 脚本
├── references/ # 加载到上下文中的文档
└── assets/ # 模板和二进制文件
为什么要打包资源? 保持 SKILL.md 简洁(低于 5,000 字)可以防止压垮 Claude 的上下文窗口。打包资源让你能够提供详细文档、自动化脚本和模板,而不会使主提示词臃肿。Claude 仅在需要时使用 渐进式披露 加载它们。
scripts/ 目录#
scripts/ 目录包含 Claude 通过 Bash 工具运行的可执行代码——自动化脚本、数据处理器、验证器或执行确定性操作的代码生成器。
作为一个例子,skill-creator 的 SKILL.md 像这样引用脚本:
When creating a new skill from scratch, always run the `init_skill.py`.
Usage:
```scripts/init_skill.py <skill-name> --path <output-directory>```
The script:
- Creates the skill directory at the specified path
- Generates a SKILL.md template with proper frontmatter and TOC
- Creates example resource directories: scripts/, references/, assets/
- Adds example files in each directory that can be customized
当 Claude 看到这条指令时,它执行 python {baseDir}/scripts/init_skill.py。{baseDir} 变量自动解析为技能的安装路径,使技能在不同环境中可移植。
使用 scripts/ 处理复杂的多步操作、数据转换、API 交互,或任何用代码比用自然语言表达逻辑更精确的任务。
references/ 目录#
references/ 目录存储 Claude 在被引用时读入其上下文的文档。这是文本内容——markdown 文件、JSON 模式、配置模板,或任何 Claude 完成任务所需的文档。
作为一个例子,mcp-creator 的 SKILL.md 像这样引用 references:
#### 1.4 Study Framework Documentation
**Load and read the following reference files:**
- **MCP Best Practices**: [📄 View Best Practices](./reference/mcp_best_practices.md)
**For Python implementations, also load:**
- **Python SDK Documentation**: Use WebFetch to load `https://...`
- [🐍 Python Implementation Guide](./reference/python_mcp_server.md)
**For Node/TypeScript implementations, also load:**
- **TypeScript SDK Documentation**: Use WebFetch to load `https://...`
- [⚡ TypeScript Implementation Guide](./reference/node_mcp_server.md)
当 Claude 遇到这些指令时,它使用 Read 工具:Read({baseDir}/references/mcp_best_practices.md)。内容被加载到 Claude 的上下文中,提供详细信息而不会弄乱 SKILL.md。
使用 references/ 存放详细文档、大型模式库、清单、API 模式,或任何对于 SKILL.md 来说太冗长但对任务必要的文本内容。
assets/ 目录#
assets/ 目录包含 Claude 通过路径引用但不加载到上下文中的模板和二进制文件。可以将这视为技能的静态资源——HTML 模板、CSS 文件、图像、配置样板或字体。
在 SKILL.md 中:
Use the template at {baseDir}/assets/report-template.html as the base.
Reference the architecture diagram at {baseDir}/assets/diagram.png.
Claude 看到文件路径但不会读取内容。相反,它可能会将模板复制到新位置,填充占位符,或在生成的输出中引用该路径。
使用 assets/ 存放 HTML/CSS 模板、图像、二进制文件、配置模板,或任何 Claude 通过路径操作而不是读入上下文的文件。
references/ 和 assets/ 之间的关键区别在于:
- references/: 通过 Read 工具加载到 Claude 上下文中的文本内容。
- assets/: 仅通过路径引用,不加载到上下文中的文件。
这种区别对上下文管理很重要。references/ 中的 10KB markdown 文件在加载时会消耗上下文 token。assets/ 中的 10KB HTML 模板则不会。Claude 只知道路径存在。
最佳实践: 始终对路径使用
{baseDir},绝不要硬编码绝对路径。这使得技能在用户环境、项目目录和不同安装之间具有可移植性。
常见技能模式 (Common Skill Patterns)#
正如所有工程领域一样,理解常见模式有助于设计有效的技能。以下是工具集成和工作流设计中最有用的模式。
模式 1: 脚本自动化 (Script Automation)#
用例: 需要多个命令或确定性逻辑的复杂操作。
此模式将计算任务卸载到 scripts/ 目录中的 Python 或 Bash 脚本。技能提示词告诉 Claude 执行脚本并处理其输出。

SKILL.md 示例:
Run scripts/analyzer.py on the target directory:
`python {baseDir}/scripts/analyzer.py --path "$USER_PATH" --output output.json`
Parse the generated `report.json` and present findings.
所需工具:
allowed-tools: "Bash(python {baseDir}/scripts/*:*), Read, Write"
模式 2: 读取 - 处理 - 写入 (Read - Process - Write)#
用例: 文件转换和数据处理。 最简单的模式——读取输入,按照指令转换它,写入输出。用于格式转换、数据清理或报告生成。
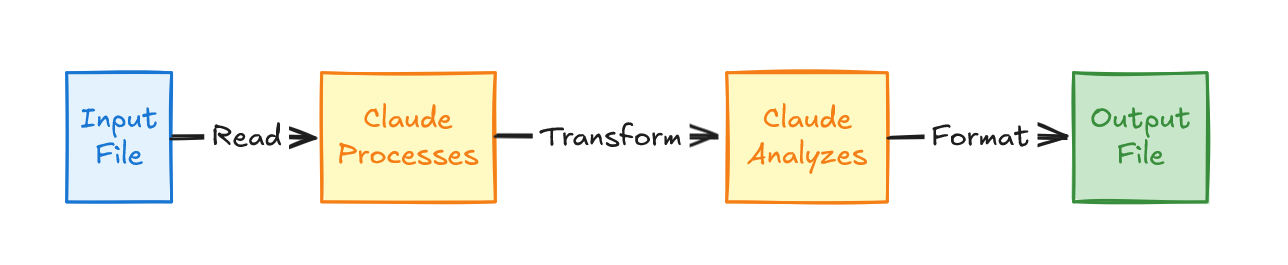
SKILL.md 示例:
## Processing Workflow
1. Read input file using Read tool
2. Parse content according to format
3. Transform data following specifications
4. Write output using Write tool
5. Report completion with summary
所需工具:
allowed-tools: "Read, Write"
模式 3: 搜索 - 分析 - 报告 (Search - Analyze - Report)#
用例: 代码库分析和模式检测。 使用 Grep 搜索代码库中的模式,读取匹配的文件以获取上下文,分析发现,并生成结构化报告。或者,搜索企业数据存储以获取数据,分析检索到的数据以获取信息,并生成结构化报告。
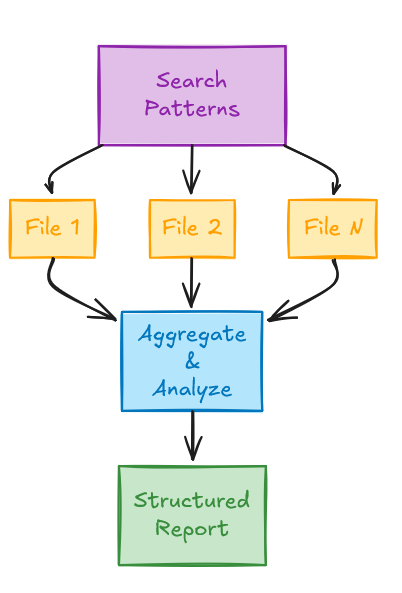
SKILL.md 示例:
## Analysis Process
1. Use Grep to find relevant code patterns
2. Read each matched file
3. Analyze for vulnerabilities
4. Generate structured report
所需工具:
allowed-tools: "Grep, Read"
模式 4: 命令链执行 (Command Chain Execution)#
用例: 有依赖关系的多步操作。 执行一系列命令,其中每一步都取决于前一步的成功。常见于类似 CI/CD 的工作流。
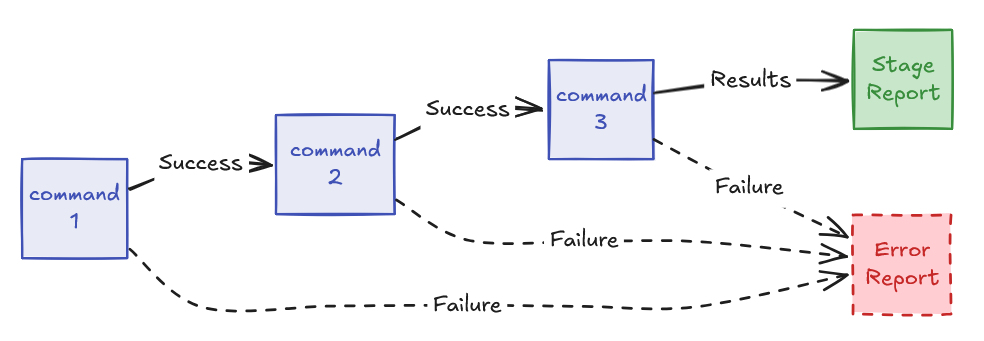
SKILL.md 示例:
Execute analysis pipeline:
npm install && npm run lint && npm test
Report results from each stage.
所需工具:
allowed-tools: "Bash(npm install:*), Bash(npm run:*), Read"
高级模式 (Advanced Patterns)#
向导式多步工作流 (Wizard-Style Multi-Step Workflows)#
用例: 每一步都需要用户输入的复杂流程。 将复杂任务分解为离散步骤,并在每个阶段之间进行明确的用户确认。用于设置向导、配置工具或引导式流程。
SKILL.md 示例:
## Workflow
### Step 1: Initial Setup
1. Ask user for project type
2. Validate prerequisites exist
3. Create base configuration
Wait for user confirmation before proceeding.
### Step 2: Configuration
1. Present configuration options
2. Ask user to choose settings
3. Generate config file
Wait for user confirmation before proceeding.
### Step 3: Initialization
1. Run initialization scripts
2. Verify setup successful
3. Report results
基于模板的生成 (Template-Based Generation)#
用例: 从存储在 assets/ 中的模板创建结构化输出。
加载模板,用用户提供或生成的数据填充占位符,并写入结果。常见于报告生成、样板代码创建或文档编写。
SKILL.md 示例:
## Generation Process
1. Read template from {baseDir}/assets/template.html
2. Parse user requirements
3. Fill template placeholders:
- {{name}} → user-provided name
- {{summary}} → generated summary
- {{date}} → current date
4. Write filled template to output file
5. Report completion
迭代式精炼 (Iterative Refinement)#
用例: 需要多次传递且深度递增的过程。 首先执行广泛分析,然后对发现的问题进行逐步深入的挖掘。用于代码审查、安全审计或质量分析。
SKILL.md 示例:
## Iterative Analysis
### Pass 1: Broad Scan
1. Search entire codebase for patterns
2. Identify high-level issues
3. Categorize findings
### Pass 2: Deep Analysis
For each high-level issue:
1. Read full file context
2. Analyze root cause
3. Determine severity
### Pass 3: Recommendation
For each finding:
1. Research best practices
2. Generate specific fix
3. Estimate effort
Present final report with all findings and recommendations.
上下文聚合 (Context Aggregation)#
用例: 结合多个来源的信息以建立全面理解。 从不同文件和工具收集数据,综合成连贯的图景。用于项目摘要、依赖分析或影响评估。
SKILL.md 示例:
## Context Gathering
1. Read project README.md for overview
2. Analyze package.json for dependencies
3. Grep codebase for specific patterns
4. Check git history for recent changes
5. Synthesize findings into coherent summary
智能体技能内部架构 (Agent Skills Internal Architecture)#
随着概述和构建过程的涵盖,我们现在可以检查 skills 在幕后实际上是如何工作的。skills 系统通过一个 元工具 (meta-tool) 架构运作,其中一个名为 Skill 的工具充当所有个体技能的容器和调度器。这种设计在实现和目的上将技能与传统工具从根本上区分开来。
Skill工具是一个管理所有技能的 元工具。
技能对象设计 (Skills Object Design)#
像 Read, Bash, 或 Write 这样的传统工具执行离散动作并返回即时结果。Skills 的运作方式不同。它们不是直接执行动作,而是将专门的指令注入对话历史,并动态修改 Claude 的执行环境。这通过两条用户消息发生——一条包含用户可见的元数据,另一条包含完整的、对 UI 隐藏但发送给 Claude 的技能提示词——并通过改变智能体的上下文来更改权限、切换模型,并在技能使用期间调整思维 token 参数。
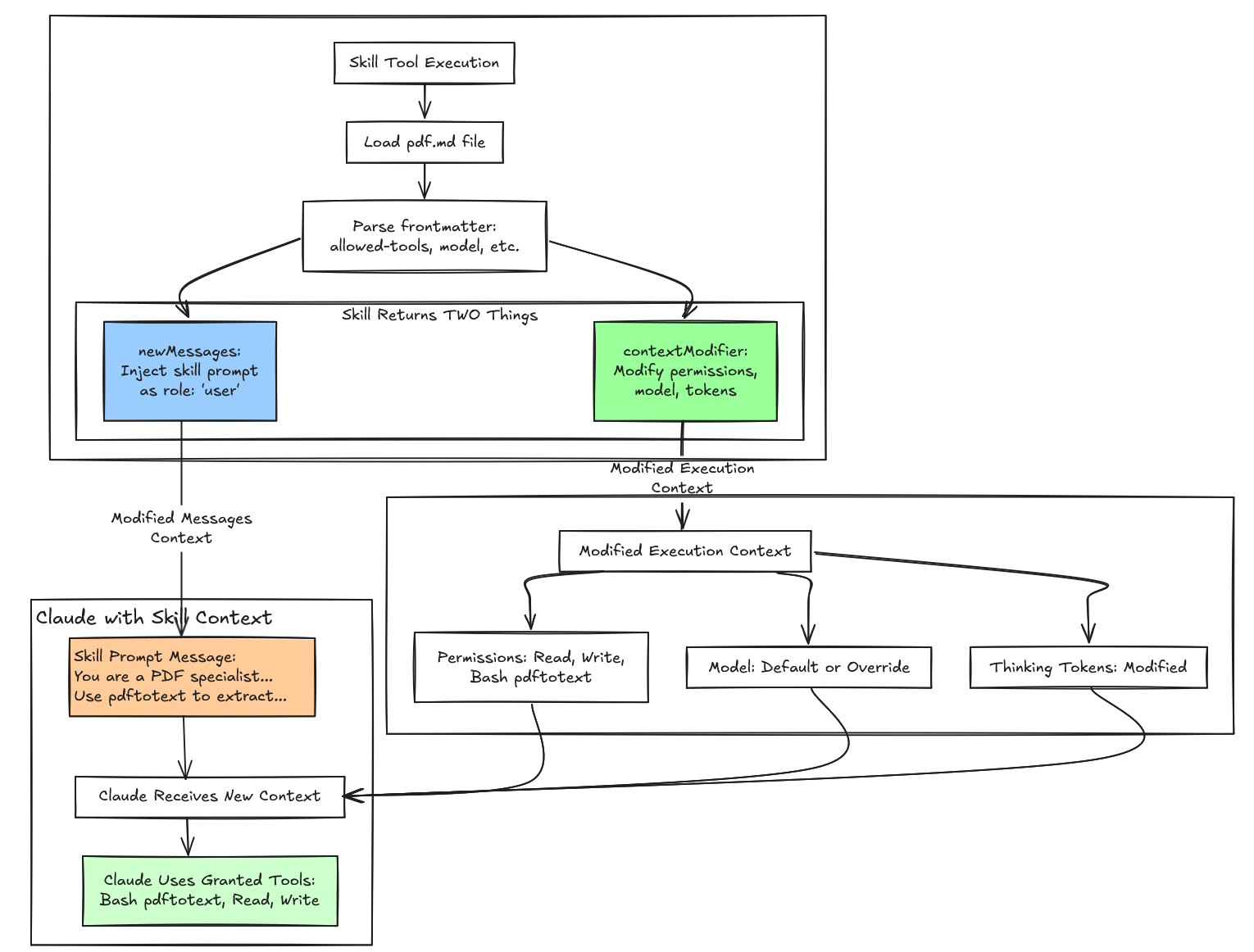
| 特性 (Feature) | 普通工具 (Normal Tool) | 技能工具 (Skill Tool) |
|---|---|---|
| 本质 | 直接动作执行者 | 提示词注入 + 上下文修改器 |
| 消息角色 | assistant → tool_use user → tool_result | assistant → tool_use Skill user → tool_result user → skill prompt ← 注入! |
| 复杂性 | 简单 (3-4 条消息) | 复杂 (5-10+ 条消息) |
| 上下文 | 静态 | 动态 (每轮修改) |
| 持久性 | 仅工具交互 | 工具交互 + 技能提示词 |
| Token 开销 | 极小 (~100 tokens) | 显著 (~1,500+ tokens 每轮) |
| 用例 | 简单,直接任务 | 复杂,引导式工作流 |
复杂性是巨大的。普通工具生成简单的消息交换——助手工具调用,随后是用户结果。技能注入多条消息,在动态修改的上下文中操作,并携带显著的 Token 开销以提供指导 Claude 行为的专门指令。
理解 Skill 元工具如何工作揭示了这个系统的机制。让我们检查它的结构:
Pd = {
name: "Skill", // 工具名称常量: $N = "Skill"
inputSchema: {
command: "string" // 例如, "pdf", "skill-creator"
},
outputSchema: {
success: "boolean",
commandName: "string"
},
// 🔑 关键字段: 这生成技能列表
prompt: async () => fN2(),
// 验证和执行
validateInput: async (input, context) => { /* 5 error codes */ },
checkPermissions: async (input, context) => { /* allow/deny/ask */ },
call: async *(input, context) => { /* yields messages + context */ }
}
prompt 字段将 Skill 工具与 Read 或 Bash 等其他具有静态描述的工具区分开来。Skill 工具不使用固定字符串,而是使用动态提示生成器,通过聚合所有可用技能的名称和描述在运行时构建其描述。这实现了 渐进式披露 (progressive disclosure) —— 系统最初只加载极简元数据(技能名称和来自前置元数据的描述)到 Claude 的初始上下文中,提供刚好足够的信息让模型决定哪个技能匹配用户的意图。完整的技能提示词仅在 Claude 做出选择后才加载,防止上下文膨胀,同时保持可发现性。
async function fN2() {
let A = await atA(),
{
modeCommands: B,
limitedRegularCommands: Q
} = vN2(A),
G = [...B, ...Q].map((W) => W.userFacingName()).join(", ");
// ...省略部分代码...
return `Execute a skill within the main conversation
<skills_instructions>
When users ask you to perform tasks, check if any of the available skills matches.
How to use skills:
- Invoke skills using this tool with the skill name only (no arguments).
- When you invoke a skill, you will see <command-message>The "{name}" skill is loading...</command-message>
- The skill's prompt will expand and provide detailed instructions.
- Examples:
- \`command: "pdf"\` - invoke the pdf skill
- \`command: "xlsx"\` - invoke the xlsx skill
- \`command: "ms-office-suite:pdf"\` - invoke using fully qualified name
Important:
- Only use skills listed in <available_skills> below
- Do not invoke a skill that is already running
- Do not use this tool for built-in CLI commands (like /help, /compact)
</skills_instructions>
<available_skills>
${Y}${J}
</available_skills>
`;
}
与某些助手(如 ChatGPT)中某些工具存在于系统提示词中不同,Claude 智能体技能不存在于系统提示词中。它们作为 Skill 工具描述的一部分存在于 tools 数组中。个别技能的名称表示为 Skill 元工具输入模式的 command 字段的一部分。为了更好地可视化它的样子,这里是实际的 API 请求结构:
{
"model": "claude-sonnet-4-5-20250929",
"system": "You are Claude Code, Anthropic's official CLI...",
"messages": [
{"role": "user", "content": "Help me create a new skill"},
// ... 对话历史
],
"tools": [ // ← 发送给 Claude 的 Tools 数组
{
"name": "Skill", // ← 元工具 (Meta-tool)
"description": "Execute a skill...\n\n<skills_instructions>...",
"input_schema": {
"type": "object",
"properties": {
"command": {
"type": "string",
"description": "The skill name (no arguments)" // ← 技能名称
}
}
}
},
{
"name": "Bash",
"description": "Execute bash commands...",
// ...
},
{
"name": "Read",
// ...
}
// ... 其他工具
]
}
<available_skills> 部分存在于 Skill 工具的描述中,并为每个 API 请求重新生成。系统通过聚合当前加载的技能(来自用户和项目配置、插件提供的技能以及任何内置技能)来动态构建此列表,默认受 15,000 个字符的 token 预算限制。这种预算限制迫使技能作者编写简洁的描述,并确保工具描述不会压垮模型的上下文窗口。
技能对话和执行上下文注入设计#
大多数 LLM API 支持 role: "system" 消息,理论上可以携带系统提示词。事实上,OpenAI 的 ChatGPT 将其默认工具携带在其系统提示词中,包括用于内存的 bio、用于任务调度的 automations、用于控制 canvas 的 canmore、用于图像生成的 img_gen、file_search、python 和用于互联网搜索的 web。最后,工具提示词占据了其系统提示词中约 90% 的 token 计数。如果我们有大量工具和/或技能要加载到上下文中,这可能有用但效率极低。
然而,系统消息具有不同的语义,使其不适合用于技能。系统消息设置跨越整个对话持久存在的全局上下文,以比用户指令更高的权威性影响所有后续轮次。
技能需要临时的、有范围的行为。skill-creator 技能应该只影响技能创建相关的任务,而不是将会话剩余部分的 Claude 转变为永久的 PDF 专家。使用 role: "user" 配合 isMeta: true 使技能提示词对 Claude 表现为用户输入,使其保持临时性并局限于当前交互。技能完成后,对话返回正常的对话上下文和执行上下文,没有残留的行为修改。
像 Read, Write, 或 Bash 这样的普通工具具有简单的通信模式。当 Claude 调用 Read 时,它发送文件路径,接收文件内容,并继续工作。用户在他们的记录中看到“Claude used the Read tool(Claude 使用了 Read 工具)”,这就是足够的透明度。工具做了一件事,返回了一个结果,交互就结束了。Skills 的运作有着根本的不同。技能不是执行离散动作并返回结果,而是注入全面的指令集,修改 Claude 推理和处理任务的方式。
这创造了一个普通工具从未面临的设计挑战:用户需要透明度了解哪些技能正在运行以及它们在做什么,而 Claude 需要详细的、可能冗长的指令来正确执行技能。如果用户在他们的聊天记录中看到完整的技能提示词,UI 就会被成千上万字的内部 AI 指令弄乱。如果技能激活完全隐藏,用户就会失去对系统代表他们所做事情的可见性。解决方案需要将这两个通信通道分离成具有不同可见性规则的独特消息。
技能系统在每条消息上使用 isMeta 标志来控制它是否出现在用户界面中。当 isMeta: false(或者当标志被省略并默认为 false)时,消息渲染在用户看到的对话记录中。当 isMeta: true 时,消息作为 Claude 对话上下文的一部分发送到 Anthropic API,但从未出现在 UI 中。这个简单的布尔标志实现了复杂的双通道通信:一条流用于人类用户,另一条用于 AI 模型。元提示 (Meta-prompting) 用于元工具 (meta-tools)!
当技能执行时,系统向对话历史注入两条独立的用户消息。第一条携带 isMeta: false 的技能元数据,使其作为状态指示器对用户可见。第二条携带 isMeta: true 的完整技能提示词,将其从 UI 中隐藏,同时使其对 Claude 可用。这种拆分解决了透明度与清晰度的权衡问题,向用户展示正在发生的事情,而不用实现细节压垮他们。
元数据消息使用简洁的 XML 结构,前端可以解析并适当地显示:
let metadata = [
`<command-message>${statusMessage}</command-message>`,
`<command-name>${skillName}</command-name>`,
args ? `<command-args>${args}</command-args>` : null
].filter(Boolean).join('\n');
// Message 1: 没有 isMeta 标志 -> 默认为 false -> 可见 (VISIBLE)
messages.push({
content: metadata,
autocheckpoint: checkpointFlag
});
例如,当 PDF 技能激活时,用户在他们的记录中看到一个干净的加载指示器:
<command-message>The "pdf" skill is loading</command-message>
<command-name>pdf</command-name>
<command-args>report.pdf</command-args>
这条消息保持故意的极简——通常 50 到 200 个字符。XML 标签使前端能够以特殊格式渲染它,验证是否存在适当的 <command-message> 标签,并维护会话期间执行了哪些技能的审计跟踪。因为省略时 isMeta 标志默认为 false,所以此元数据自动出现在 UI 中。
技能提示词消息采取相反的方法。它从 SKILL.md 加载完整内容,可能用附加上下文扩充它,并显式设置 isMeta: true 以对用户隐藏它:
let skillPrompt = await skill.getPromptForCommand(args, context)
// 如果需要,使用 prepend/append 内容进行扩充
let fullPrompt = prependContent.length > 0 || appendContent.length > 0
? [...prependContent, ...appendContent, ...skillPrompt]
: skillPrompt;
// Message 2: 显式 isMeta: true -> 隐藏 (HIDDEN)
messages.push({
content: fullPrompt,
isMeta: true // 对 UI 隐藏, 发送给 API
});
典型的技能提示词包含 500 到 5,000 字,提供全面的指导以改变 Claude 的行为。PDF 技能提示词可能包含:
You are a PDF processing specialist.
Your task is to extract text from PDF documents using the pdftotext tool.
## Process
1. Validate the PDF file exists
2. Run pdftotext command to extract text
3. Read the output file
4. Present the extracted text to the user
## Tools Available
You have access to:
- Bash(pdftotext:*) - For running pdftotext command
- Read - For reading extracted text
- Write - For saving results if needed
## Output Format
Present the extracted text clearly formatted.
Base directory: /path/to/skill
User arguments: report.pdf
此提示词建立了任务上下文,概述了工作流,指定了可用工具,定义了输出格式,并提供了环境特定路径。带有标题、列表和代码块的 markdown 结构帮助 Claude 解析并遵循指令。有了 isMeta: true,这整个提示词被发送到 API 但从不弄乱用户的记录。
除了核心元数据和技能提示词外,技能还可以为附件和权限注入额外的条件消息:
let allMessages = [
createMessage({ content: metadata, autocheckpoint: flag }), // Message 1
createMessage({ content: skillPrompt, isMeta: true }), // Message 2
// ...attachmentMessages,
// ... (allowedTools.length || skill.model ? [
// createPermissionsMessage({
// type: "command_permissions",
// allowedTools: allowedTools,
// model: skill.useSmallFastModel ? getFastModel() : skill.model
// })
// ] : [])
];
附件消息可以携带诊断信息、文件引用或补充技能提示词的附加上下文。权限消息仅在技能在其前置元数据中指定 allowed-tools 或请求模型覆盖时出现,提供修改运行时执行环境的元数据。这种模块化组合允许每条消息都有特定用途,并根据技能的配置被包含或排除,扩展了基本的双消息模式以处理更复杂的场景,同时通过 isMeta 标志保持相同的可见性控制。
为什么是两条消息而不是一条? (Why Two Messages Instead of One?)#
单消息设计将迫使做出不可能的选择。设置 isMeta: false 会使整个消息可见,将成千上万字的 AI 指令倾倒在用户的聊天记录中。用户会看到类似这样的东西:
┌─────────────────────────────────────────────┐
│ The "pdf" skill is loading │
│ │
│ You are a PDF processing specialist. │
│ │
│ Your task is to extract text from PDF │
│ documents using the pdftotext tool. │
│ │
│ ## Process │
│ │
│ 1. Validate the PDF file exists │
│ 2. Run pdftotext command to extract text │
│ 3. Read the output file │
│ ... [500 more lines] ... │
└─────────────────────────────────────────────┘
UI 变得不可用,充满了给 Claude 而不是给人类看的内部实现细节。或者,设置 isMeta: true 会隐藏一切,不提供关于哪个技能被激活或它接收了什么参数的透明度。用户将无法看到系统代表他们正在做什么。
双消息拆分通过给每条消息不同的 isMeta 值解决了这个问题。
- 消息 1 带有
isMeta: false提供面向用户的透明度。 - 消息 2 带有
isMeta: true为 Claude 提供详细指令。
这种细粒度的控制实现了透明度而不会信息过载。
这些消息也服务于根本不同的受众和目的:
| 方面 (Aspect) | 元数据消息 (Metadata Message) | 技能提示词消息 (Skill Prompt Message) |
|---|---|---|
| 受众 | 人类用户 | Claude (AI) |
| 目的 | 状态/透明度 | 指令/指导 |
| 长度 | ~50-200 字符 | ~500-5,000 字 |
| 格式 | 结构化 XML | 自然语言 markdown |
| 可见性 | 应该是可见的 | 应该是隐藏的 |
| 内容 | “正在发生什么?” | “如何做?” |
代码库甚至通过不同的路径处理这些消息。元数据消息被解析以寻找 <command-message> 标签,经过验证,并格式化用于 UI 显示。技能提示词消息直接发送到 API 而不经过解析或验证——它是仅供 Claude 推理过程使用的原始指令内容。合并它们将违反单一职责原则 (Single Responsibility Principle),强迫一条消息通过两个不同的处理管道服务于两个不同的受众。
案例研究:执行生命周期 (Case Study: Execution Lifecycle)#
现在涵盖了智能体技能的内部架构,让我们通过以一个假设的 pdf 技能作为案例研究,检查当用户说“Extract text from report.pdf(从 report.pdf 提取文本)”时发生的完整执行流程。
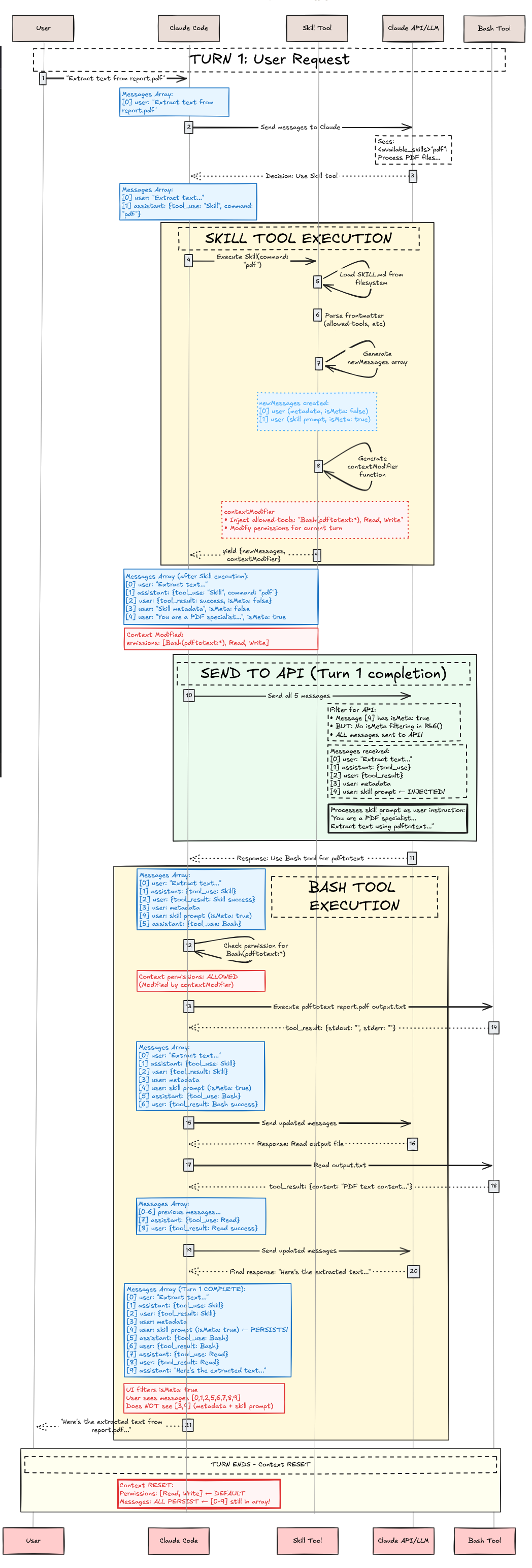
第一阶段:发现与加载(启动)(Phase 1: Discovery & Loading)#
当 Claude Code 启动时,它扫描技能:
async function getAllCommands() {
// Load from all sources in parallel
let [userCommands, skillsAndPlugins, pluginCommands, builtins] =
await Promise.all([
loadUserCommands(), // ~/.claude/commands/
loadSkills(), // .claude/skills/ + plugins
loadPluginCommands(), // Plugin-defined commands
getBuiltinCommands() // Hardcoded commands
]);
return [...userCommands, ...skillsAndPlugins, ...pluginCommands, ...builtins]
.filter(cmd => cmd.isEnabled());
}
具体的技能加载逻辑:
// Specific skill loading
async function loadPluginSkills(plugin) {
// ...
const skillFiles = findSkillMdFiles(plugin.skillsPath);
const skills = [];
for (const file of skillFiles) {
const content = readFile(file);
const { frontmatter, markdown } = parseFrontmatter(content);
skills.push({
type: "prompt",
name: `${plugin.name}:${getSkillName(file)}`,
description: `${frontmatter.description} (plugin:${plugin.name})`,
whenToUse: frontmatter.when_to_use, // ← Note: underscore to camelCase
allowedTools: parseTools(frontmatter['allowed-tools']),
model: frontmatter.model === "inherit" ? undefined : frontmatter.model,
isSkill: true,
promptContent: markdown,
// ... other fields
});
}
return skills;
}
对于 pdf 技能,这产生:
{
type: "prompt",
name: "pdf",
description: "Extract text from PDF documents (plugin:document-utils)",
whenToUse: "When user wants to extract or process text from PDF files",
allowedTools: ["Bash(pdftotext:*)", "Read", "Write"],
model: undefined, // Uses session model
isSkill: true,
disableModelInvocation: false,
promptContent: "You are a PDF processing specialist...",
// ... other fields
}
第二阶段:第一轮 - 用户请求与技能选择 (Phase 2: Turn 1 - User Request & Skill Selection)#
用户发送请求:“Extract text from report.pdf”。Claude 接收此消息以及工具数组中的 Skill 工具。在 Claude 决定调用 pdf 技能之前,系统必须在 Skill 工具的描述中呈现可用技能。
技能过滤与呈现 (Skill Filtering & Presentation)#
并非所有加载的技能都出现在 Skill 工具中。技能必须在前置元数据中具有 description 或 when_to_use,否则会被过滤掉。过滤标准:
async function getSkillsForSkillTool() {
const allCommands = await getAllCommands();
return allCommands.filter(cmd =>
cmd.type === "prompt" &&
cmd.isSkill === true &&
!cmd.disableModelInvocation &&
(cmd.source === "builtin" || cmd.isModeCommand === true) &&
(cmd.hasUserSpecifiedDescription || cmd.whenToUse) // ← 必须有描述
);
}
技能格式化 (Skill Formatting)#
每个技能都被格式化用于 <available_skills> 部分。作为一个例子,我们假设的 pdf 技能可能被格式化为:
"pdf": Extract text from PDF documents - When user wants to extract or process text from PDF files
function formatSkill(skill) {
let name = skill.name;
let description = skill.whenToUse
? `${skill.description} - ${skill.whenToUse}`
: skill.description;
return `"${name}": ${description}`;
}
Claude 的决策过程 (Claude’s Decision Process)#
现在,当用户提示:“Extract text from report.pdf”。Claude 接收带有 Skill 工具的 API 请求,读取 <available_skills>,并进行推理(假设地,因为我们看不到推理痕迹):
Internal reasoning:
- User wants to "extract text from report.pdf"
- This is a PDF processing task
- Looking at available skills...
- "pdf": Extract text from PDF documents - When user wants to extract...
- This matches! The user wants to extract text from a PDF
- Decision: Invoke Skill tool with command="pdf"
注意这里没有算法匹配。没有词法匹配。没有语义匹配。没有搜索。这是纯粹的 LLM 推理,基于技能的描述做出决定。一旦完成,Claude 返回一个工具使用:
{
"type": "tool_use",
"id": "toolu_123abc",
"name": "Skill",
"input": {
"command": "pdf"
}
}
第三阶段:技能工具执行 (Phase 3: Skill Tool Execution)#
Skill 工具现在执行。这对应于序列图中黄色的“SKILL TOOL EXECUTION”框,它在产生结果之前执行验证、权限检查、文件加载和上下文修改。
步骤 1:验证 (Validation)#
async validateInput({ command }, context) {
let skillName = command.trim().replace(/^\//, "");
// Error 1: Empty
if (!skillName) return { result: false, errorCode: 1 };
// Error 2: Unknown skill
const allSkills = await getAllCommands();
if (!skillExists(skillName, allSkills)) {
return { result: false, errorCode: 2 };
}
// ... 其他检查 (无法加载, 模型禁用, 非 Prompt 类型)
return { result: true };
}
pdf 技能通过所有验证检查 ✓
步骤 2:权限检查 (Permission Check)#
async checkPermissions({ command }, context) {
// ... 获取当前权限上下文 ...
// 检查拒绝规则
// ...
// 检查允许规则
// ...
// 默认: 询问用户
return { behavior: "ask", message: `Execute skill: ${skillName}` };
}
假设没有规则,用户被提示:“Execute skill: pdf?” 用户批准 ✓
步骤 3:加载技能文件并生成执行上下文修改 (Load Skill File & Generate Execution Context Modification)#
随着验证和权限获得批准,Skill 工具加载技能文件并准备执行上下文修改:
async *call({ command }, context) {
// ... 获取技能对象 ...
// Load the skill prompt
const promptContent = await skill.getPromptForCommand("", context);
// Generate metadata tags
const metadata = [/* ... */].join('\n');
// Create messages
const messages = [
{ type: "user", content: metadata }, // Visible to user
{ type: "user", content: promptContent, isMeta: true }, // Hidden
// ... attachments, permissions
];
// Extract configuration
const allowedTools = skill.allowedTools || [];
const modelOverride = skill.model;
// Yield result with execution context modifier
yield {
type: "result",
data: { success: true, commandName: skillName },
newMessages: messages,
// 🔑 执行上下文修改函数
contextModifier(context) {
let modified = context;
// 注入允许的工具 (Pre-approve tools)
if (allowedTools.length > 0) {
// ... 更新 toolPermissionContext ...
}
// 覆盖模型
if (modelOverride) {
// ... 更新 mainLoopModel ...
}
return modified;
}
};
}
Skill 工具产生其结果,包含 newMessages(元数据 + 技能提示词 + 用于对话上下文注入的权限)和 contextModifier(用于执行上下文修改的工具权限 + 模型覆盖)。这完成了序列图中黄色的“SKILL TOOL EXECUTION”框。
第四阶段:发送到 API(第一轮完成)(Phase 4: Send to API (Turn 1 Completion))#
系统构建完整的消息数组发送到 Anthropic API。这包括来自对话的所有消息加上新注入的技能消息:
{
"model": "claude-sonnet-4-5-20250929",
"messages": [
{
"role": "user",
"content": "Extract text from report.pdf"
},
{
"role": "assistant",
"content": [
{
"type": "tool_use",
"name": "Skill",
"input": { "command": "pdf" }
}
]
},
{
"role": "user",
"content": "<command-message>The \"pdf\" skill is loading...</command-message>"
// isMeta: false (default) - UI 可见
},
{
"role": "user",
"content": "You are a PDF processing specialist...\n\n## Process...",
"isMeta": true // UI 隐藏, 发送给 API
},
{
"role": "user",
"content": {
"type": "command_permissions",
"allowedTools": ["Bash(pdftotext:*)", "Read", "Write"],
"model": undefined
}
}
]
}
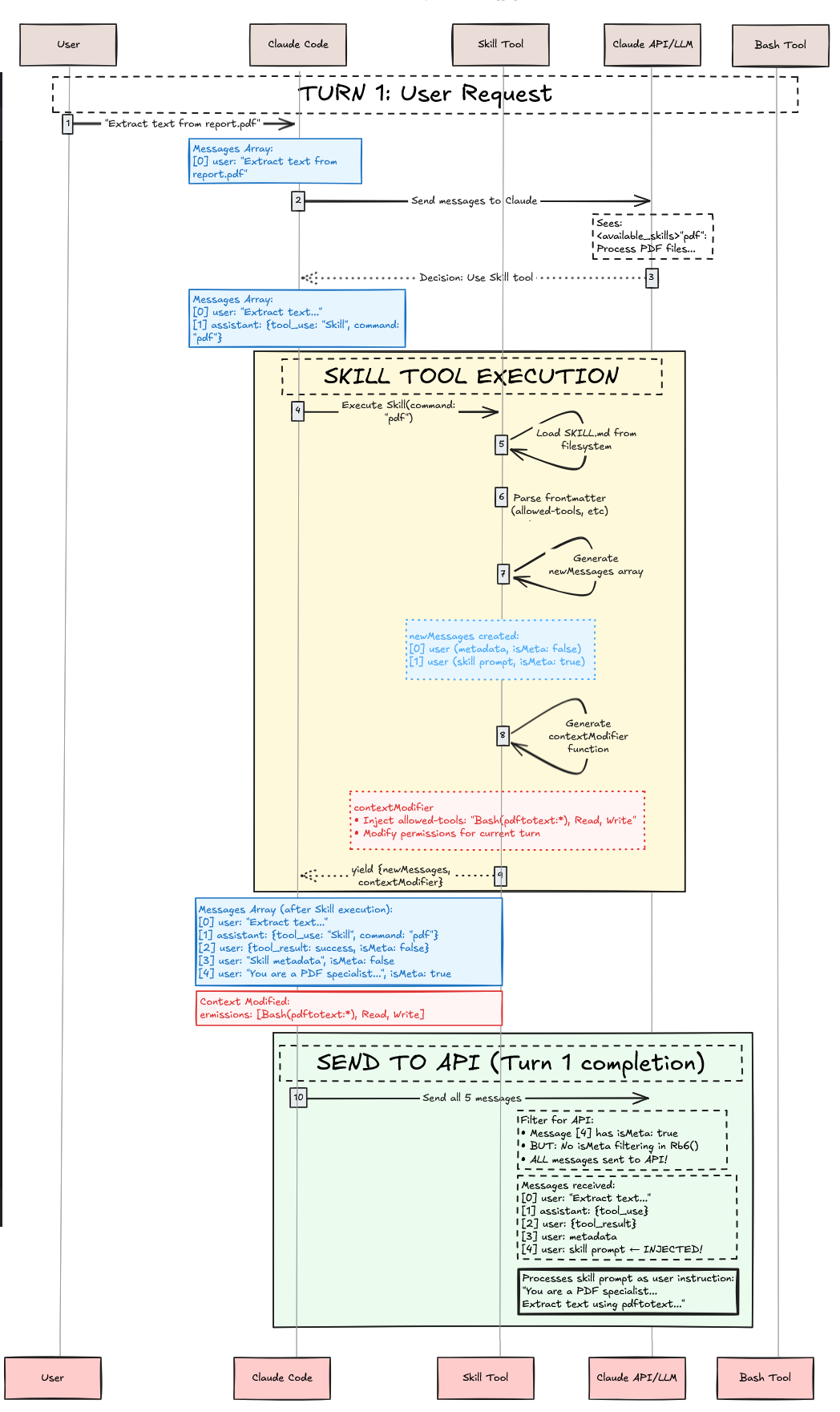
以上显示了我们到目前为止所做的工作。应用了执行上下文修饰符,为后续的工具调用预批准了 Bash(pdftotext:*), Read, 和 Write。请求被发送到 Anthropic API。这结束了技能执行。如果这是一个普通工具,我们就完成了。然而,技能是不同的。智能体技能仅仅注入了对话上下文和执行上下文。这意味着我们仍然需要用所有这些注入的上下文调用 Claude 智能体来完成用户的请求!
第五阶段:Bash 工具执行(带有技能上下文的工具使用!)(Phase 5: Bash Tool Execution (Tool use with Skill Context!))#
Claude 接收带有注入的对话上下文的 API 响应。技能提示词已经改变了 Claude 的行为,为其提供:
- 专门的 PDF 处理指令(对话上下文)
- 对
Bash(pdftotext:*),Read, 和Write工具的预批准访问(执行上下文) - 要遵循的清晰工作流(对话上下文)
Claude 处理上下文并遵循 pdf 技能的工作流:
I'll extract text from report.pdf. Let me process the file.
[Following pdf skill's instructions]
1. Validate that report.pdf exists
2. Run pdftotext command to extract text
3. Read the output file
4. Present the extracted text to you
Claude 使用 Bash 工具(预先批准,无需用户提示):
{
"type": "tool_use",
"id": "toolu_456def",
"name": "Bash",
"input": {
"command": "pdftotext report.pdf output.txt",
"description": "Extract text from PDF using pdftotext"
}
}
Bash 工具成功执行,返回结果。然后 Claude 使用 Read 工具读取输出文件并将提取的文本呈现给用户。技能成功引导 Claude 完成了专门的 PDF 提取工作流,通过将指令注入对话上下文并修改工具权限的执行上下文。
结论:心智模型回顾 (Conclusion: The Mental Model Recap)#
Claude Code 中的技能是 基于提示词的对话和执行上下文修改器,通过元工具架构工作:
关键要点:
- 技能是
SKILL.md文件中的 提示词模板,不是可执行代码。 - Skill 工具(大写 S)是
tools数组中管理个体技能的 元工具,不在系统提示词中。 - 技能通过注入指令提示词(通过
isMeta: true消息)来修改 对话上下文。 - 技能通过更改工具权限和模型选择来修改 执行上下文。
- 选择通过 LLM 推理 发生,而不是算法匹配。
- 工具权限通过执行上下文修改 限定于技能执行范围。
- 技能每次调用注入两条用户消息——一条用于用户可见的元数据,一条用于发送到 API 的隐藏指令。
优雅的设计:通过将专业知识视为修改对话上下文的 提示词 和修改执行上下文的 权限,而不是执行的 代码,Claude Code 实现了传统函数调用难以企及的灵活性、安全性和可组合性。