
1. 引言:Agent 设计困境#
在构建如 Deep Research 或 Claude Code 等现代 Agent 系统时,开发者通常采用 “压缩器-预测器”(Compressor-Predictor) 的复合架构:
- 压缩器 (Compressor):负责处理海量原始数据(如 100 篇搜索结果),将其提炼为精简摘要。
- 预测器 (Predictor):基于摘要进行推理,生成最终用户答案。
然而,当前的系统设计往往陷入“试错循环”:当系统回答错误时,是压缩器漏掉了关键信息,还是预测器推理能力不足?为了回答这个问题,工程师通常需要运行昂贵的端到端评估。
这篇论文提出了一种范式转移:将 Agent 系统视为信息通信过程。通过引入信息论(Information Theory)作为数学框架,作者量化了模型间的信息流动,并揭示了关于计算资源分配的 Scaling Laws。
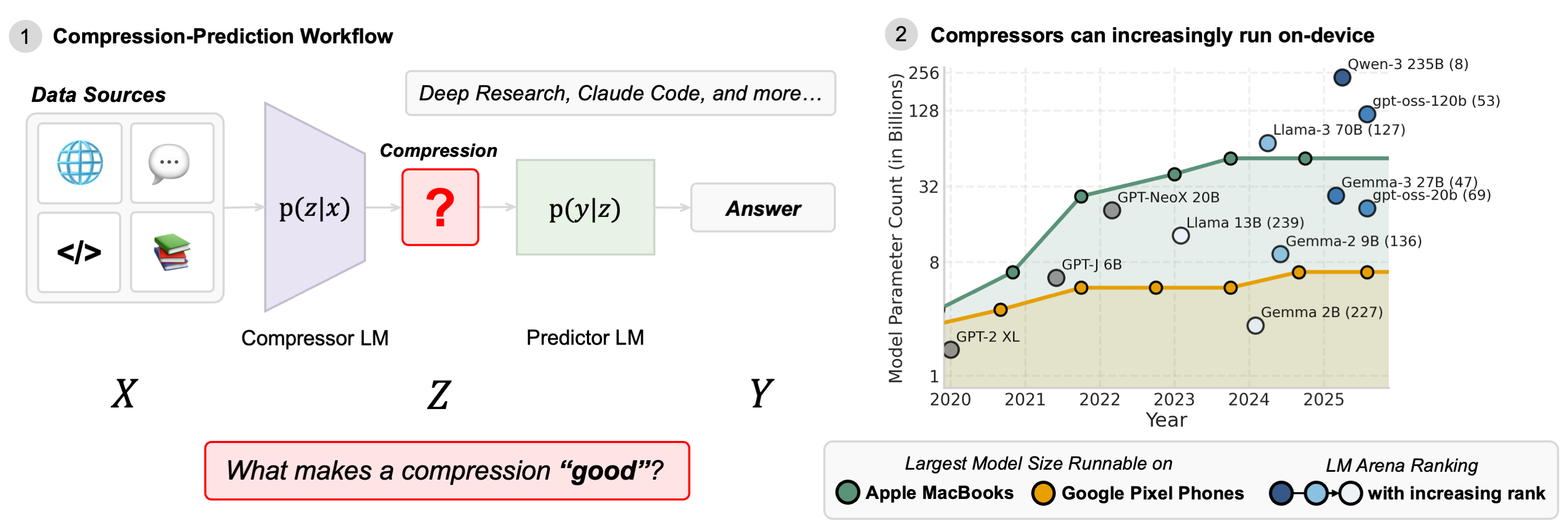
2. 理论框架:作为“噪声信道”的压缩器#
作者将压缩过程建模为一个马尔可夫链:
$$ X \xrightarrow{p(z|x)} Z \xrightarrow{p(y|z)} Y $$- \(X\):原始长上下文。
- \(Z\):压缩后的摘要(由压缩器 \(p(z|x)\) 生成)。
- \(Y\):最终预测结果(由预测器 \(p(y|z)\) 生成)。
在此框架下,压缩器不仅仅是一个总结工具,更是一个有损噪声信道(Noisy Channel)。设计的核心目标是在压缩率(Rate)和失真度(Distortion)之间寻找平衡。
为了在不运行下游预测任务的情况下评估压缩质量,作者提出了基于 互信息(Mutual Information, MI) 的评估指标 \(I(X; Z)\)。通过蒙特卡洛估计器,该指标可以直接利用现代推理引擎(如 SGLang)输出的 Log Probabilities 进行计算:
理论定义
- \(I(X; Z)\):表示变量 \(X\) 和 \(Z\) 之间的互信息。直观上,它衡量知道 \(Z\) 能减少多少关于 \(X\) 的不确定性。
- \(\mathbb{E}_{x,z \sim p(x,z)}\):这是对联合分布 \(p(x,z)\) 求期望。意味着在整个数据集上考虑所有成对的 \((x, z)\)。
- \(p(z|x)\):这是条件概率(或编码器分布),即给定输入 \(x\) 生成 \(z\) 的概率。
- \(\mathbb{E}_{x'} [p(z|x')]\):分母部分实际上是边缘分布 \(p(z)\) 的展开形式。因为直接计算 \(p(z)\) 很困难(需要在所有可能的 \(x\) 上积分),这里写成了期望形式 \(p(z) = \int p(z|x')p(x')dx'\)。
- 核心逻辑:互信息的本质是 \(KL(p(x,z) || p(x)p(z))\)。公式里的项 \(\log \frac{p(z|x)}{p(z)}\) 也就是 点互信息 (PMI)。如果 \(z\) 和 \(x\) 强相关,分子 \(p(z|x)\) 会远大于分母 \(p(z)\)(随机出现的概率),对数值就会很大。
蒙特卡洛估计器(近似计算):
由于在实际操作中无法遍历真实的概率分布,需要通过采样来近似计算:
- \(\frac{1}{NM} \sum_{i=1}^{N} \sum_{j=1}^{M}\):这是对外部期望 \(\mathbb{E}_{x,z}\) 的蒙特卡洛近似。
- \(N\):表示采样的输入样本(Contexts)数量,即 Batch size。
- \(M\):表示对于每一个输入 \(x_i\),采样生成的 \(z\) 的数量。
- \(\log p(z_{ij}|x_i)\):对应第一行分子的对数。这计算了生成的 \(z_{ij}\) 与其原本对应的输入 \(x_i\) 之间的匹配度(Log-likelihood)。
- \(\log \left( \frac{1}{N} \sum_{l=1}^{N} p(z_{ij}|x_l) \right)\):对应第一行分母 \(p(z)\) 的对数。
- 这是一个边缘概率的估计。
- 它通过将当前的 \(z_{ij}\) 与 Batch 中所有其他输入 \(x_l\) 进行配对来计算。
- 直观理解:看这个 \(z_{ij}\) 在整个数据集中出现的“普遍程度”。
- \(\hat{I}(X; Z)\):最终得到的互信息估计值。
这个公式展示了如何在一个 Batch 的数据中,利用 对比(Contrastive) 的思想来计算互信息:
- 计算 \(z\) 和它真正来源 \(x\) 的匹配度(正样本对)。
- 减去 \(z\) 和所有 \(x\) 的平均匹配度(近似边缘分布)。
- 两者的差值越大,说明 \(z\) 包含的关于 \(x\) 的独特信息越多,互信息越高。如果一个摘要是“正确的废话”(笼统概述,丢失具体数据等信息),那么它在任何文档下生成的概率都很高,两项相减接近,互信息就很低。
关键:MI 仅依赖于压缩器输出的统计特性,是一个 与任务无关(Task-Agnostic) 的质量代理指标。
3. 深度拆解:压缩与预测的 Scaling Paradox#
论文通过在 LongHealth、FinanceBench、FineWeb 等数据集上的大规模实验,揭示了违反直觉的 Scaling 现象。这一章节不仅挑战了传统的算力分配直觉,还提供了精确的数据支撑。
3.1 压缩器的 Scaling Law:算力增长的“次线性”红利#
通常直觉认为,模型参数量越大,推理成本越高。但在 Agent 的压缩环节,作者观察到了极其特殊的现象:更大的模型反而更“省”算力。
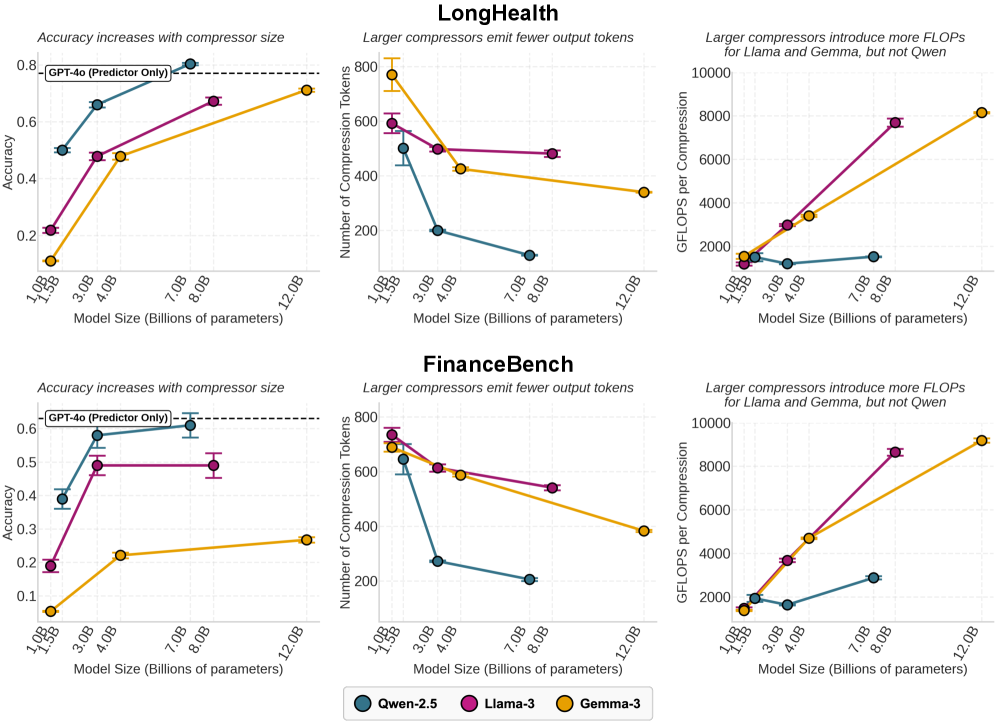
论文 图2 和 图3 的实验数据:
- 精简度红利 (Conciseness):在 LongHealth 数据集上,Qwen-2.5 7B 模型生成的摘要长度显著短于 1.5B 模型。更大的模型能更精准地抓住重点,抛弃冗余信息,其生成的 Token 数量最高可减少 4.6倍。
- FLOPs 的次线性增长:推理的总计算量(FLOPs)近似等于 \(\text{Model Size} \times \text{Generated Tokens}\)。虽然 7B 模型的参数量是 1.5B 的近 5 倍,但由于它生成的 Token 数大幅减少,相互抵消后,FLOPs-per-generation 仅增加了 1.3%。
- 性能飞跃:在消耗几乎相同算力的情况下,7B 模型的下游准确率比 1.5B 模型高出 3.1倍,甚至超越了 GPT-4o 单独作为预测器的 Baseline 约 4个百分点。
这揭示了一个工程真理:在压缩任务中,智能(参数量)即效率。
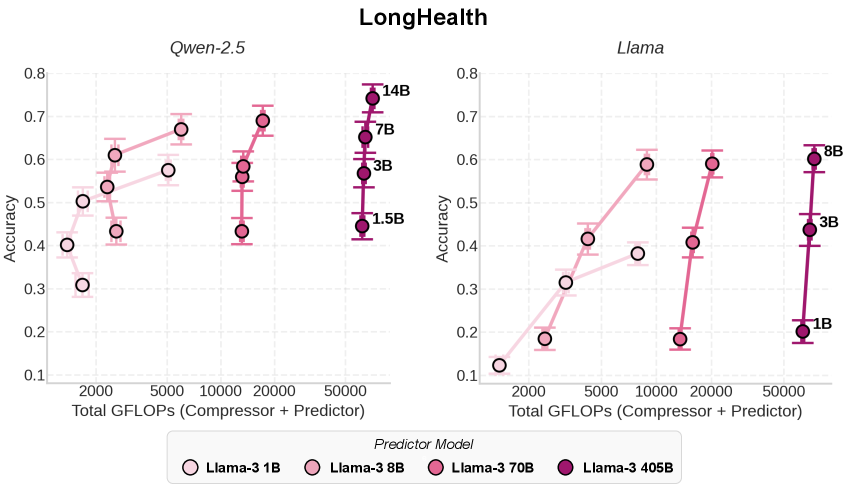
3.2 资源分配决断:Bottleneck 到底在哪里?#
论文在 Section 3.1 提出了一个关键的工程问题:如果预算有限,应该把算力投在“压缩器”还是“预测器”?
图3数据给出了明确答案:
- 压缩器主导性:将压缩器(Qwen-2.5)从 1B 扩展到 7B,下游 QA 准确率提升了惊人的 60%。
- 预测器边际效应递减:固定压缩器,将后端预测器(Llama-3)从 70B 扩展到庞大的 405B,准确率仅提升了 12%。
压缩器构成了系统的信息瓶颈(Information Bottleneck)。如果压缩器产生的摘要 \(Z\) 丢失了 \(X\) 中的关键事实(如日期、数值),后端的预测器无论推理能力多强(哪怕是 GPT-4o 或 Llama-3-405B),都无法凭空恢复这些信息。这也就是作者所说的“归因问题”——大部分性能损失实际上源于前端的压缩失真。
4. 率-失真(Rate-Distortion)分析:量化信息密度#
为了不依赖昂贵的下游任务(如 QA 准确率)来评估压缩器,作者引入了率-失真理论。这部分分析为如何选择模型提供了数学依据。
4.1 比特效率(Bit Efficiency)#
作者定义了一个新指标:Bit Efficiency,即每输出一个 Token 所包含的互信息量(MI per token)。
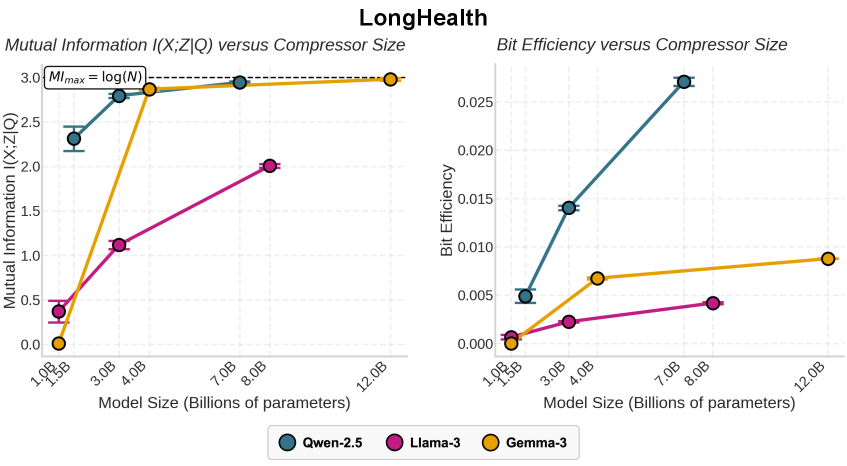
- 如图4所示,更大的模型(如 7B)不仅总互信息更高,其 Bit Efficiency 也显著更高。这意味着大模型输出的每一个字都更“干货”,含金量更高。
- 相比之下,小模型(1B级别)倾向于“啰嗦且无效”,生成大量 token 却无法有效编码原始上下文中的关键信息。
4.2 率-失真曲线的拟合#
在 图6(左) 中,作者展示了基于实验数据的 \(R-D\) 曲线。横轴为 Rate(信息率),纵轴为 Distortion(\(1 - \text{Accuracy}\))。
- 曲线形态:数据完美拟合了指数衰减函数 \(D(R) \approx C e^{-bR} + D_0\)。
- 预测器的天花板:图中不同颜色的曲线代表不同规模的预测器(1B, 8B, 70B, 405B)。值得注意的是,随着压缩器 Rate 的提升,所有预测器的失真度都迅速下降。但当 Rate 达到一定阈值后,曲线趋于平缓(\(D_0\)),此时再大的预测器也无法进一步降低失真。
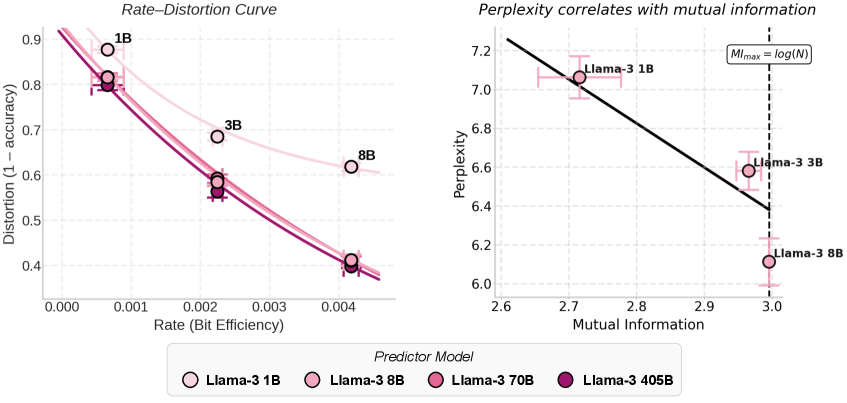
4.3 互信息作为通用代理指标#
图6(右) 在 FineWeb 数据集上,作者发现:
- 强相关性:压缩器的互信息率(Rate)与模型困惑度(Perplexity)之间的皮尔逊相关系数达到 \(r = -0.84\) (\(R^2 = 0.71\))。
- 意义:这意味着开发者可以在不运行任何特定问答任务的情况下,仅仅通过计算 MI 来评估和筛选压缩器模型。如果一个压缩器的 MI 高,它在下游几乎所有任务(无论是抽取式问答还是创造性生成)上的表现都会更好。
5. 实战演练:Deep Research 系统的极致优化#
论文在 Section 3.5 和 Appendix D.6 中,将上述理论应用到了目前最火热的 Deep Research 场景(类似于 OpenAI Deep Research 或 Perplexity Pro)。
5.1 工作流重构#

作者设计了一个标准化的 Deep Research Pipeline(见 图8):
- 分解:预测器将大问题分解为多个
(Query, Subtask)对。 - 并行压缩:多个压缩器并行运行,分别进行搜索、阅读网页,并根据 Subtask 生成摘要。
- 综合:预测器汇总所有摘要生成最终报告。
使用 DeepResearch Bench 和 RACE 评分体系(衡量全面性、深度、指令遵循、可读性)进行评估。
5.2 惊人的降本增效数据#
对比基准(Uncompressed GPT-4o,即直接把搜索到的 Raw HTML 喂给 GPT-4o)与优化方案(本地 Qwen-2.5 压缩器 + GPT-4o 预测器):
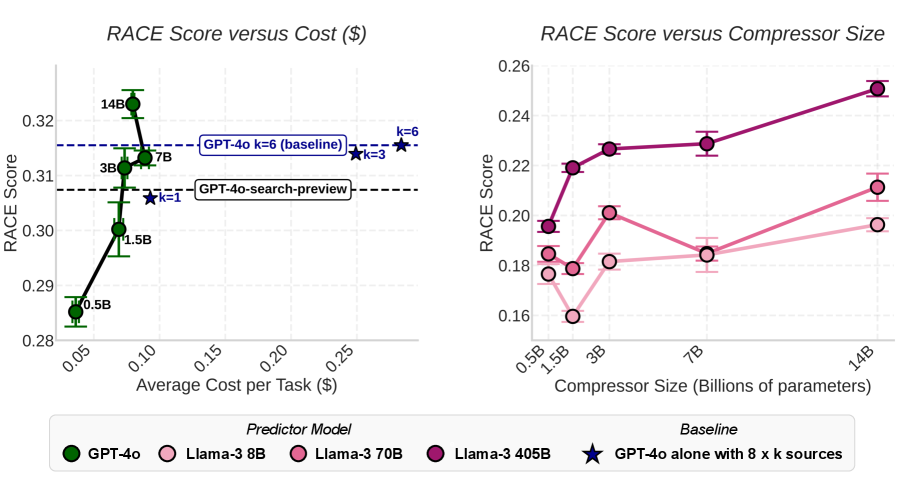
成本暴跌 (图7左):
- 优化方案的 API 成本仅为基准的 26% - 28%。
- 原因在于:大量的 Raw HTML 处理(Reading/Compressing)被转移到了本地运行的开源模型(如 Qwen-2.5)上,这些本地算力几乎是“免费”的。只有高度浓缩的摘要才会被发送给昂贵的 GPT-4o API。
性能无损甚至反超 (图7右):
- 使用 14B 的 Qwen-2.5 作为本地压缩器时,最终报告的 RACE 评分比基准 高出 2.3%。
- 极小模型的潜力:即使使用极小的 3B 模型作为压缩器,也能恢复基准 99% 的性能,同时节省 74% 的成本。
这一结果有力地证明了:Front-loading(前端重载)策略 ——即在本地用较强的模型处理数据压缩——是构建低成本、高性能 Agent 的关键路径。
6. 面向工程师的设计原则#
基于以上分析,论文提出了四条 Agent 系统设计原则:
- 压缩器规模可实现次线性计算成本增长:不要害怕在前端使用大模型,它们生成的 Token 更少,总计算量可能持平甚至更低。
- 前端重载(Front-load)算力:将计算资源向压缩端倾斜。与其依赖云端的超大模型处理所有 Token,不如在本地运行强大的压缩模型。
- 优化信息密度:关注互信息(MI)指标。模型并不是记得越多越好,而是要以最高的密度传递有效信息。
- 模型家族差异:不同模型家族的压缩特性不同。本研究中,Qwen-2.5 在压缩任务上的算力效率和 Scaling 表现优于 Llama-3 和 Gemma-3。
总结#
这篇文章将 Agent 系统设计从经验主义推向了理论指导。在多模型协作系统中,“通信带宽”的质量(即压缩器的互信息保留能力)决定了系统的上限。通过在数据入口处部署更大、更智能的压缩器,不仅能解决“上下文腐烂(Context Rot)”问题,还能在保持高性能的同时显著降低推理成本。