
- 链接:arXiv:2511.20639
- 代码:GitHub
TL;DR#
- 核心问题:现有的基于 LLM 的多智能体系统(MAS)依赖自然语言(文本)进行通信,导致信息丢失(连续转离散)、低效(解码/编码开销大)以及高计算复杂度。
- 核心贡献:
- LatentMAS 框架:提出首个完全在连续潜在空间(Latent Space)内进行推理和通信的免训练多智能体框架。
- 关键机制:
- 潜在思维生成:自回归生成最后一层隐藏状态而非 Token。
- 线性对齐算子:通过 \(W_a\) 矩阵解决潜在状态与输入嵌入的分布对齐问题。
- 潜在工作记忆传输:通过 KV Cache 的直接拼接实现无损信息传递。
- 理论支撑:证明了潜在思维比文本具有更高的表达能力(Theorem 3.1),且通信是无损的(Theorem 3.3),计算复杂度显著降低(Theorem 3.4)。
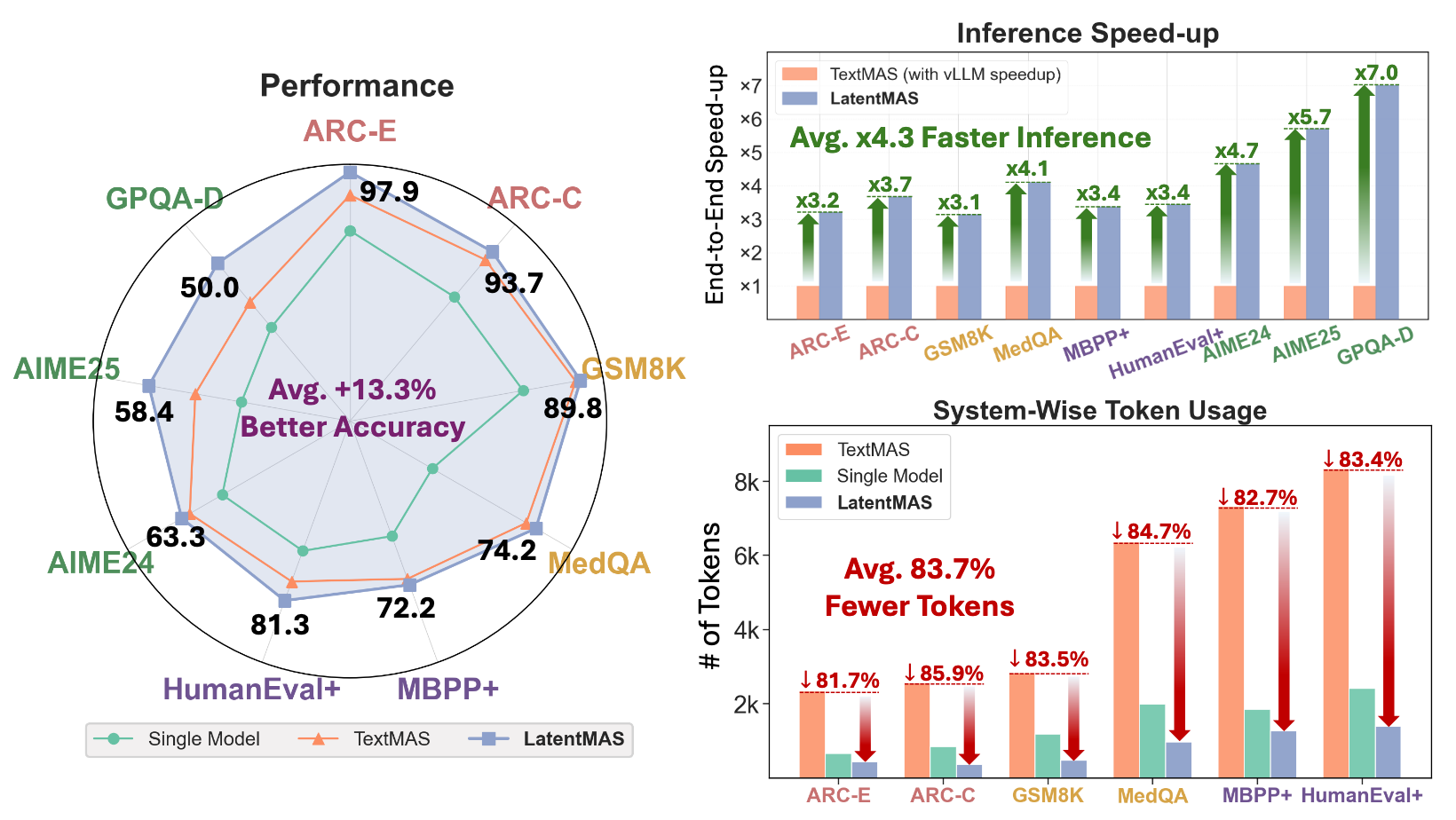
- 实证结果:在 9 个基准测试中,准确率提升高达 14.6%,Token 减少约 80%,推理速度提升 4 倍以上。
1. 痛点:Token 是多智能体协作的“带宽杀手”#
在现有的多智能体系统(MAS)中,自然语言(Text)被视为“通用语(Lingua Franca)”。然而,从信息论的角度看,这是一种极度低效的压缩方式。
- 信息有损:Transformer 内部的高维隐藏状态(Hidden States, \(h \in \mathbb{R}^{d_h}\))包含了丰富的概率分布和语义细微差别,但在输出时被迫坍缩为离散的 Token ID。
- 计算冗余:智能体 A 生成 Token 需要解码,智能体 B 接收 Token 需要重新编码(Prefill)。
LatentMAS 的核心直觉:如果智能体之间“脑波(Latent States)”相通,我们就不需要笨重地“说话”了。
2. 核心架构:LatentMAS 的技术实现#
LatentMAS 是一个端到端、免训练的框架。如下图所示,它将协作过程完全下沉到了潜在空间。
2.1 架构概览#
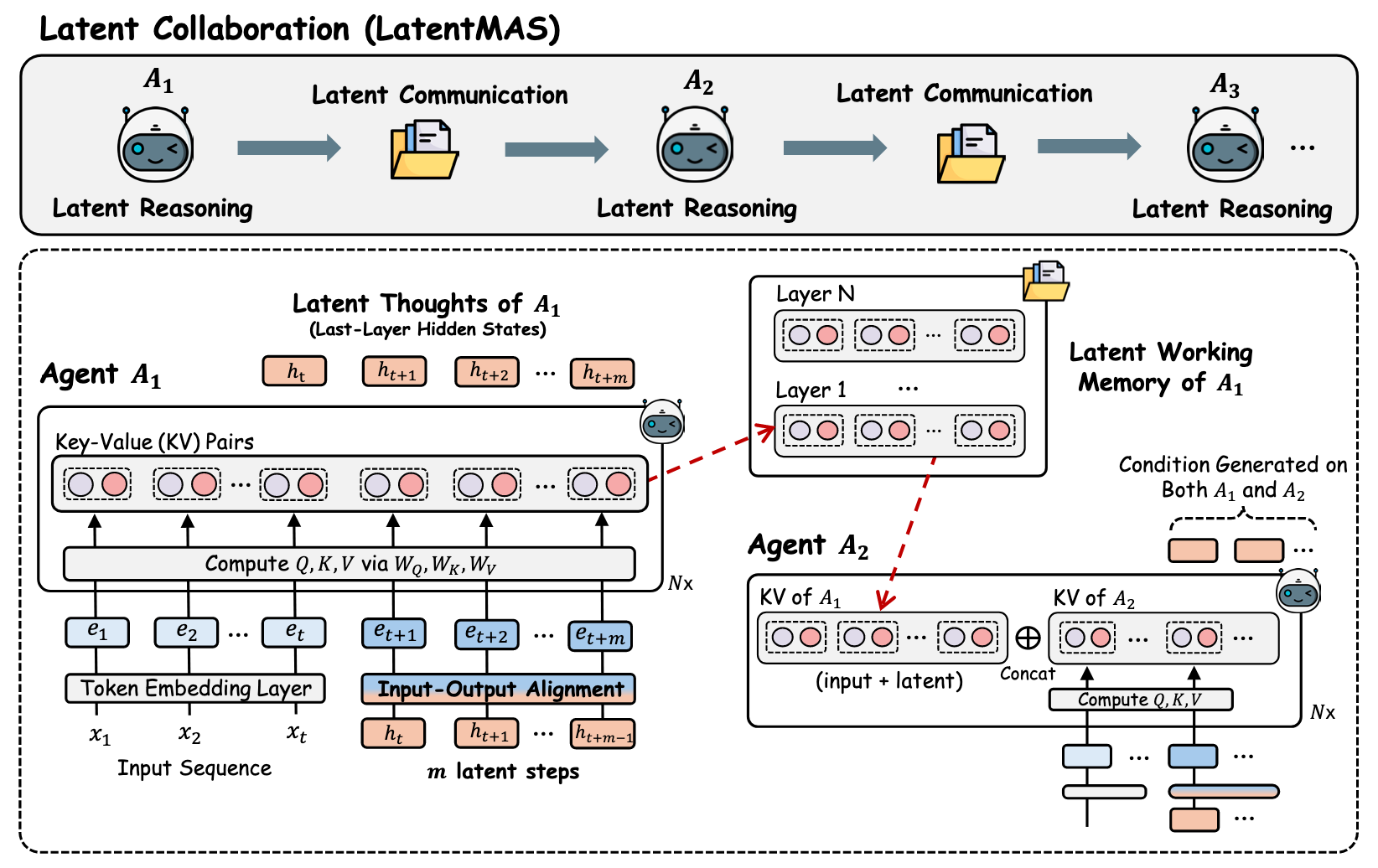
- Latent Reasoning(潜在推理):智能体不再输出 Token,而是让最后一层的 Hidden State 在模型内部自回归循环。
- Latent Communication(潜在通信):智能体 A 的 KV Cache 直接被“嫁接”到智能体 B 的注意力层中。
2.2 关键技术一:自回归潜在思维与分布对齐 (Distribution Alignment)#
这是论文中最具数学美感的部分。模型直接将 \(t\) 时刻的输出 \(h_t\) 作为 \(t+1\) 时刻的输入。
挑战:输出嵌入空间(Output Space)和输入嵌入空间(Input Space)的分布并不一致(Distribution Shift)。直接回环会导致 OOD(Out-of-Distribution)问题。
解决方案:引入线性对齐算子 \(W_a\)。 作者并不重新训练模型,而是通过数学方法寻找一个投影矩阵 \(W_a \in \mathbb{R}^{d_h \times d_h}\),使得输出向量 \(h\) 映射回输入空间 \(e\):
$$ e = h W_a, \quad \text{其中} \quad W_a \approx W_{\text{out}}^{-1} W_{\text{in}} $$由于 \(W_{\text{out}}\) 通常不可逆(非方阵或奇异),作者在附录 A.1 中指出,通过 岭回归(Ridge Regression) 求解该问题,引入正则化项 \(\lambda\) 以保证数值稳定性:
$$ W_a = (W_{\text{out}}^\top W_{\text{out}} + \lambda I)^{-1} W_{\text{out}}^\top W_{\text{in}} $$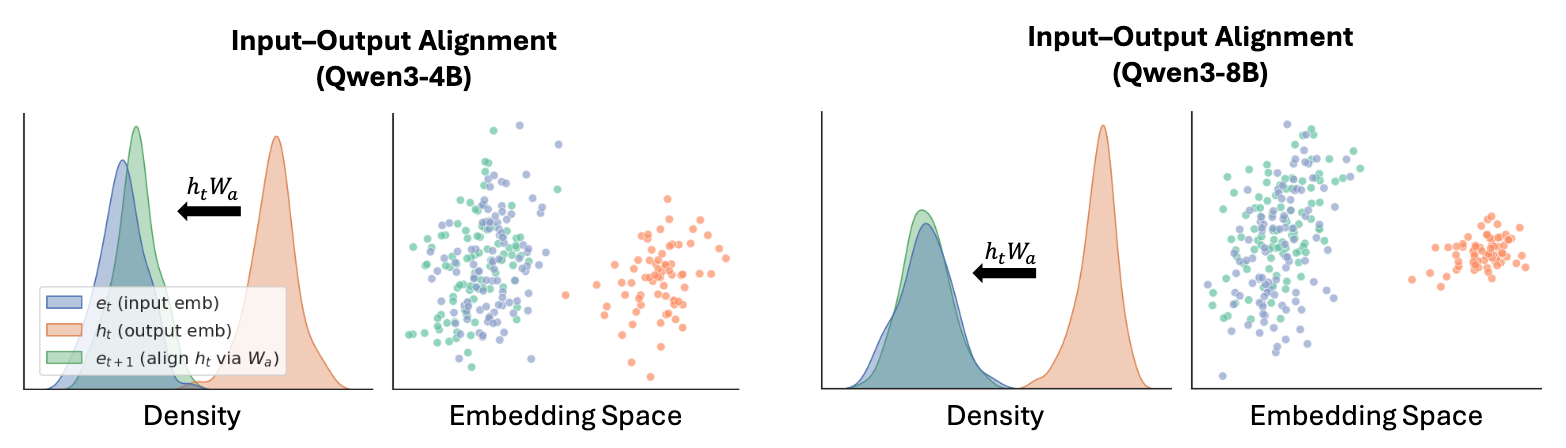
- 未对齐 (\(h_t\)):灰色区域。可以看到生成的隐藏状态偏离了原始 Token Embedding 的流形分布。
- 对齐后 (\(e_{t+1}\)) / 真实输入 (\(e_t\)):绿色与橙色区域。经过 \(W_a\) 投影后,潜在向量完美重合回了合法的输入分布空间。
- 结论:这一步是 LatentMAS 免训练且能稳定推理的数学基石。
2.3 关键技术二:无损工作记忆传输 (KV Cache Transfer)#
在 LatentMAS 中,智能体 \(A_1\) 的输出不是文本,而是其计算过程中产生的所有层的 KV Cache 集合 \(\mathcal{M}_{A_1}\):
$$ \mathcal{M}_{A_1} = \left\{ (K_{A_1, \text{cache}}^{(l)}, V_{A_1, \text{cache}}^{(l)}) \mid l = 1, \dots, L \right\} $$智能体 \(A_2\) 接收这些记忆时,直接将其拼接到自己的 Cache 中。这不仅实现了零开销的信息读取,更重要的是实现了无损信息传递。
3. 理论深度:为什么“向量”优于“文本”?#
论文给出了两个强有力的定理来支撑这一架构的优越性。
定理 3.1:潜在思维的表达能力 (Expressiveness)#
假设存在线性表示假设,如果用文本无损地表达长度为 \(m\) 的潜在思维,所需的文本长度至少为:
$$ \text{Length}_{\text{text}} = \Omega\left( \frac{d_h \cdot m}{\log |\mathcal{V}|} \right) $$- 参数解读:\(d_h\) 是隐藏层维度(如 4096),\(|\mathcal{V}|\) 是词表大小(如 150k)。
- 推论:由于 \(d_h\) 很大,1 个潜在步(Latent Step)承载的信息量相当于数百个 Token。这就是为什么 LatentMAS 能用极少的步数完成复杂推理。
定理 3.4:复杂度分析 (Complexity)#
基于文本的 MAS 复杂度受制于漫长的 Token 生成过程。LatentMAS 的时间复杂度显著降低:
- TextMAS 复杂度:\(\approx O(d_h^3 m^2 / \log^2 |\mathcal{V}|)\) (受限于等效文本长度的平方)
- LatentMAS 复杂度:\(O((d_h^2 m + d_h m^2)L)\)
4. 实验数据#
实验在 9 个基准测试上进行,涵盖数学 (GSM8K, AIME)、科学 (GPQA) 和代码 (HumanEval)。
4.1 核心性能表#
下表展示了在 MAS 设置下,LatentMAS 对比单模型和 TextMAS 的提升(以 Qwen3-14B 为例):
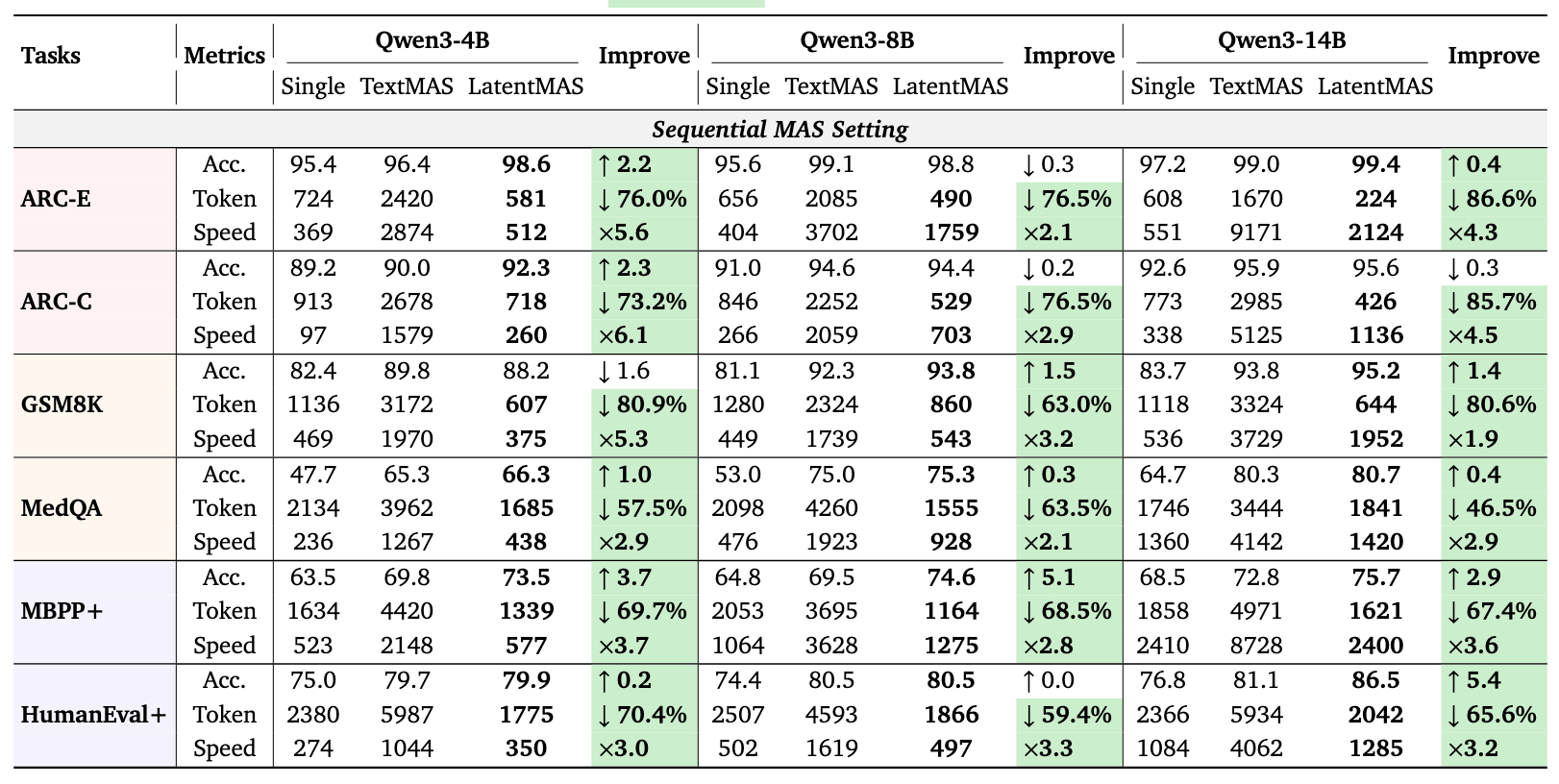
数据解读:
- 极速推理:在 ARC-E 任务上,LatentMAS 比 TextMAS 快了 4.3倍。
- 极度省 Token:在 GSM8K 上,Token 消耗减少了 80.6%。这是因为智能体间的通信不消耗 Output Token。
- 能力增强:在代码任务 HumanEval+ 上,准确率显著提升 5.4%,证明了潜在空间协作能激发更强的推理能力。
4.2 案例分析:纠错能力的本质#


- 场景:GSM8K 数学题,需要多步计算。
- TextMAS 失败原因:Planner 输出了包含细微逻辑错误的文本。Solver 只能基于这段错误的文本继续推理,导致错误传播 (Error Propagation)。
- LatentMAS 成功原因:由于传递的是高维 KV Cache,Solver 接收到的是 Planner 的“原始思维流”。即使 Planner 的初步倾向有误,Solver 也能利用其强大的解码头和自身推理能力,在潜在空间中重构(Re-interpret) 正确的逻辑路径,从而输出正确答案。
5. 总结与批判性思考#
5.1 创新点总结#
- 打破模态壁垒:首次证明了多智能体协作不需要“翻译”成人类语言,直接交换“脑电波”更高效。
- 数学保证:通过 \(W_a\) 投影解决了潜在空间游走(Drift)的问题,提供了坚实的理论支撑。
- 工程友好:不需要微调模型,完全兼容现有的 KV Cache 机制(如 vLLM),即插即用。
5.2 局限性与挑战 (Critical Review)#
作为审稿视角的补充,本文也存在以下限制:
- 同构约束 (Homogeneity Constraint): 目前 LatentMAS 强依赖于 KV Cache 的直接拼接。这意味着协作的智能体必须拥有完全相同的 Transformer 架构(层数 \(L\)、维度 \(d_h\)、头数 \(H\) 必须一致)。你无法让 Qwen-72B 指导 Qwen-7B,也无法让 GPT-4 与 Llama-3 潜在协作。这是目前最大的落地阻碍。
- 黑盒调试困难 (The Black Box): 在 TextMAS 中,我们可以看 Log 知道 Planner 说了什么蠢话。但在 LatentMAS 中,中间交互全是浮点数矩阵。如果系统出错,人类难以介入调试。
- 通信带宽压力: 虽然节省了 Token 生成计算,但在分布式系统中传输 KV Cache(尤其是长上下文时)带来的显存带宽(VRAM Bandwidth)和网络带宽压力,远大于传输几百个文本 Token。这更适合单机多卡环境,而非跨节点的云端 API。
LatentMAS 是 Agent 系统向“原生 AI 协作(Native AI Collaboration)”迈出的关键一步,它牺牲了可解释性,换取了极致的效率和表达力。