
在当今数据驱动的世界中,网络(或图)无处不在,从社交网络、电商平台到文献引用网络。这些真实世界的网络往往具有高度的复杂性,具体表现为:
- 异构性(Heterogeneity)
- 多重性(Multiplexity)
- 属性化(Attributed)
如何为这种复杂的**属性化多重异构网络(AMHENs)**学习到高质量的节点表示(Embedding),是推荐系统、广告、节点分类等下游任务取得成功的关键。然而,现有方法大多难以同时兼顾网络的异构性、多重性和属性信息,并且在面对动辄数百万节点、数十亿边的大规模网络时,其高昂的计算和内存开销往往令人望而却步。
为了解决这些挑战,来自烟台大学、京东金融等机构的研究者在CIKM 2020会议上提出了一种名为 FAME (Fast Attributed Multiplex Heterogeneous network Embedding) 的框架。FAME以其卓越的效率和效果,为大规模AMHEN的表示学习问题提供了一个全新的解决方案。本文将深入解析FAME模型的设计思想和技术细节。
一、 核心挑战与问题定义#
在深入模型之前,我们首先要明确FAME试图解决的核心挑战:
- 异构性与多重性的融合:如何在一个统一的框架内,自动地、无需手动定义元路径(meta-path),就能捕捉和融合网络中不同类型的节点、关系以及它们之间复杂的交互模式?
- 全局结构与节点属性的保留:如何确保学习到的节点向量既能反映网络的高阶拓扑结构,又能融入节点自身的属性信息?
- 大规模网络的可扩展性:如何设计一个足够轻量级的算法,使其能够在拥有数百万节点和边的大规模网络上快速执行,而无需依赖昂贵的分布式计算平台?
基于此,论文将AMHEN的表示学习问题形式化定义如下:
问题1 (AMHEN Embedding): 给定一个属性化多重异构网络 \(G = \{V, \mathcal{E}, X\}\),其中 \(V\) 是节点集,\(\mathcal{E}\) 是多重关系边集,\(X\) 是节点属性矩阵。目标是学习一个映射函数 \(f: V \rightarrow \mathbb{R}^d\),将每个节点 \(v_i \in V\) 映射到一个低维(\(d \ll |V|\))的向量表示,即嵌入(Embedding)。
二、 FAME模型架构详解#
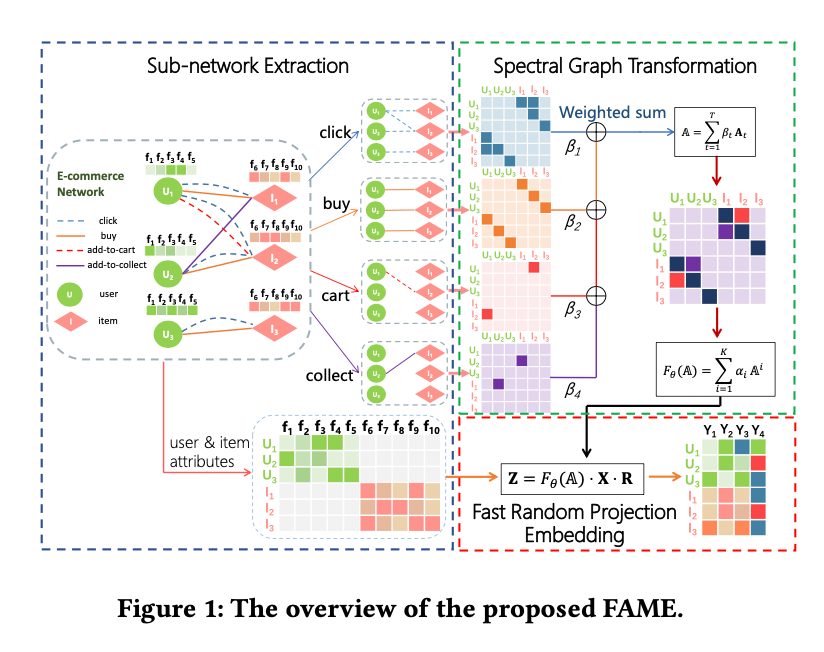
FAME的整体架构如论文中的 图1 所示,其核心思想是“先融合,再投影”。整个过程分为两个关键步骤:谱图变换 (Spectral Graph Transformation) 和 快速随机投影嵌入 (Fast Random Projection Embedding)。
第一步:谱图变换 (Spectral Graph Transformation) - 捕捉多重关系与高阶结构#
这一步的目标是,将原始网络中不同类型的关系(边)融合成一个能体现复杂交互信息的单一关系表示,并捕捉节点间的高阶邻近性。
- 网络分解:首先,FAME将复杂的AMHEN分解为多个简单的子网络。每个子网络 \(G_r\) 只包含一种类型的关系 \(r\)。例如,在电商网络中,可以将网络分解为“用户-商品点击”子网络、“用户-商品购买”子网络等。每个子网络 \(G_r\) 对应一个邻接矩阵 \(A_r\)。
- 加权融合:为了融合不同关系的重要性,FAME对所有子网络的邻接矩阵进行加权求和,得到一个拓展的邻接矩阵 \(\mathbb{A}\)。
其中,\(|\mathcal{R}|\) 是关系类型的总数,\(\beta_r\) 是一个可学习或预设的权重,代表了关系类型 \(r\) 的重要性。例如,“购买”关系的重要性(权重)通常会高于“点击”。
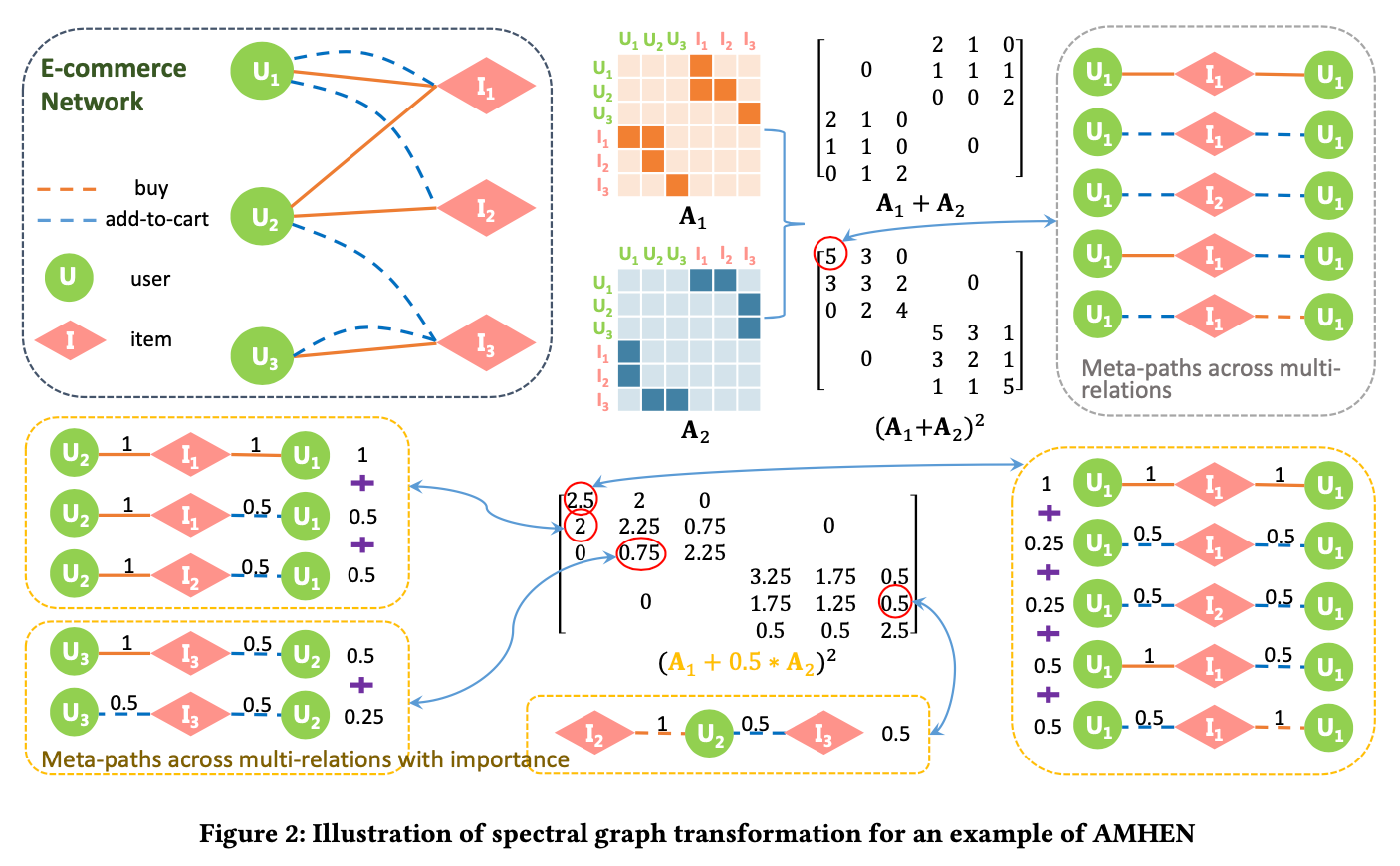
- 高阶邻近性建模:邻接矩阵的一次方 \(\mathbb{A}^1\) 只能表示节点间的直接连接(1跳邻居)。为了捕捉更长的、跨越不同关系的元路径结构(如 “用户1 -> 商品 -> 用户2”),FAME利用了邻接矩阵幂的特性:\(\mathbb{A}^i\) 的元素 \((\mathbb{A}^i)_{uv}\) 表示从节点 \(u\) 到节点 \(v\) 长度为 \(i\) 的路径数量。FAME通过对不同阶数的邻接矩阵幂进行加权求和,来构建一个综合性的变换函数 \(F(\mathbb{A})\)。
这里,\(K\) 是考虑的最高阶数(最长路径长度),\(\alpha_i\) 是一个递减的权重,反映了“路径越短,节点关系越紧密”的普遍假设。通过这个变换,FAME能够在一个矩阵 \(F(\mathbb{A})\) 中同时编码短距离和长距离、跨多种关系的复杂结构信息,而无需手动枚举元路径。这一过程在论文的 图2 中有生动的展示。
- 归一化:为了消除网络中度数高的节点带来的数据倾斜问题,FAME在执行谱图变换前,会对融合后的邻接矩阵 \(\mathbb{A}\) 进行归一化处理。
其中 \(D\) 是 \(\mathbb{A}\) 的度矩阵。
第二步:快速随机投影嵌入 (Fast Random Projection Embedding) - 实现高效降维#
谱图变换虽然强大,但如何将其与节点特征高效地结合并降维,是决定模型可扩展性的关键。传统的图卷积网络(GCN)虽然在这方面取得了巨大成功,但其固有的复杂性使其难以胜任大规模网络的挑战。
1. 传统谱图GCN的瓶颈
为了理解FAME的创新,我们首先需要回顾一下标准谱图GCN的工作原理。其核心思想是在图的傅里叶域(谱域)中进行卷积操作。一个信号(节点特征)\(X\) 在网络上的卷积可以表示为:
$$ g_\theta \star X = \Phi g_\theta(\Lambda)\Phi^T X $$其中,\(g_\theta(\Lambda)\) 是一个作用于图谱(特征值对角矩阵\(\Lambda\))上的滤波器,由参数 \(\theta\) 控制。为了捕捉局部信息,这个滤波器通常被设计成一个 \(K\) 阶多项式:
$$ g_\theta(\Lambda) = \sum_{k=1}^K \theta_k \Lambda^k $$当我们将这个理论应用到节点表示学习中,为了从 \(m\) 维的输入特征生成 \(d\) 维的嵌入,滤波器参数就需要从一个向量 \(\theta\) 扩展为一个庞大的参数矩阵 \(\Theta \in \mathbb{R}^{K \times m \times d}\)。最终的嵌入计算公式变为:
$$ Z = \sigma(\Phi(\sum_{k=1}^K \Lambda^k)\Phi^T X \Theta_k) \quad (8) $$瓶颈就在这里! 这个公式清楚地揭示了两个问题:
- 参数量巨大:需要学习和优化的参数数量为 \(K \times m \times d\)。当节点特征维度 \(m\) 很高时,这个参数量会爆炸式增长。
- 计算复杂度高:整个滤波操作的复杂度与网络中的边数成线性关系,对于大规模网络而言,训练过程将非常耗时。
2. FAME的解决方案:用固定投影替换可学习滤波器
FAME的核心创新在于,它彻底抛弃了上述复杂且需要学习的滤波器 \(g_\Theta\),代之以一个极为高效的、固定的、非学习的操作。它用两个部分来共同实现“滤波”和“降维”:
- 谱图变换 \(F(\mathbb{A})\):在前一步已经计算好,它扮演了捕捉多阶邻域结构的角色,等效于传统GCN中的 \(\sum \Lambda^k\) 部分。
- 稀疏随机投影矩阵 \(R\):它取代了需要学习的庞大参数矩阵 \(\Theta_k\)。这个矩阵 \(R \in \mathbb{R}^{m \times d}\) 的元素是固定的,根据以下稀疏规则生成,无需任何训练:
其中 \(s\) 是一个控制稀疏度的参数(如 \(s=\sqrt{m}\))。
3. 最终嵌入计算与极致优化
通过这种替换,FAME的最终嵌入计算公式变得异常简洁:
$$ Z = F(\mathbb{A}) \cdot X \cdot R = \sum_{i=1}^{K} \alpha_i \mathbb{A}^i \cdot X \cdot R $$更进一步,为了解决直接计算 \(\mathbb{A}^i\) 的高昂成本,FAME利用矩阵乘法的结合律进行终极优化。它将计算顺序从 \((A * A) * X * R\) 调整为 \(A * (A * X * R)\)。具体地,令 \(Z^1 = \mathbb{A}·X·R\),则 \(Z^i = \mathbb{A}Z^{i-1}\)。最终的嵌入为:
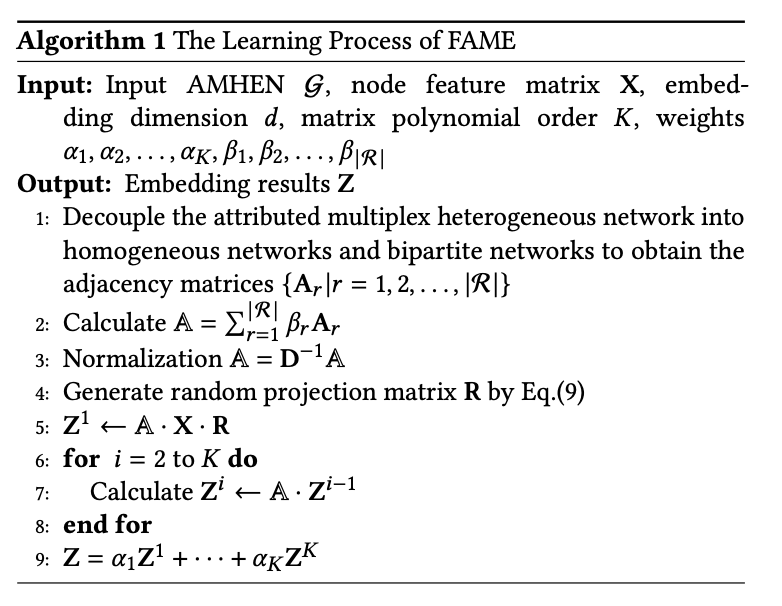
$$ Z = \sum_{i=1}^{K} \alpha_i Z^i $$这个简单的变换将每一步的计算复杂度从依赖于节点数 \(n\) 的平方或立方(\(O(n^3·K+n^2·m+n·m·d)\))降低到只与边的数量 \(e\) 线性相关(\(O(K \cdot e \cdot n + n·m·d)\)),对于稀疏图而言,这是巨大的效率提升。整个学习流程在论文的 算法1 中有清晰的伪代码描述。
三、 实验效果#
FAME的有效性和高效性在论文的实验部分得到了充分验证(详见论文 表4 至 表7):
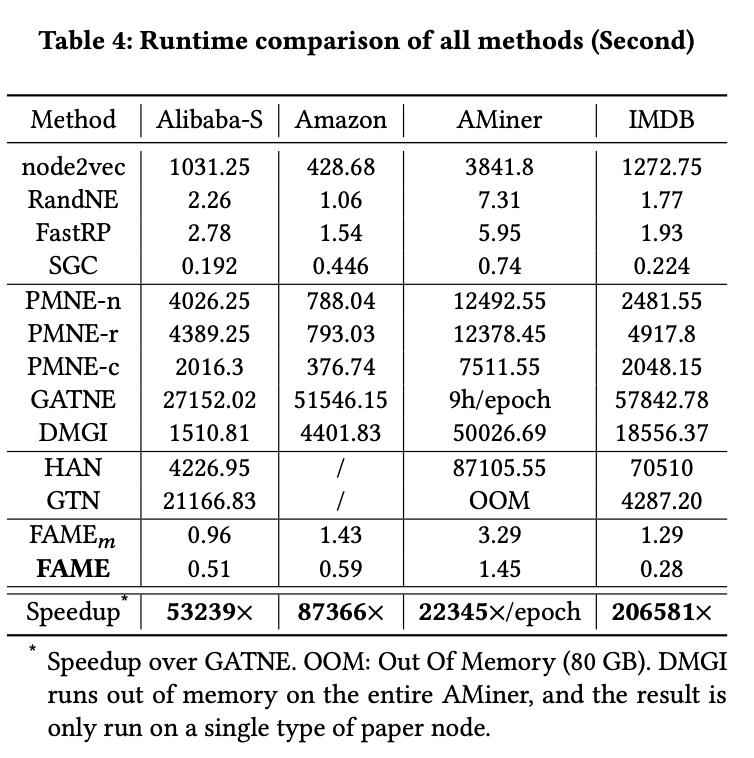
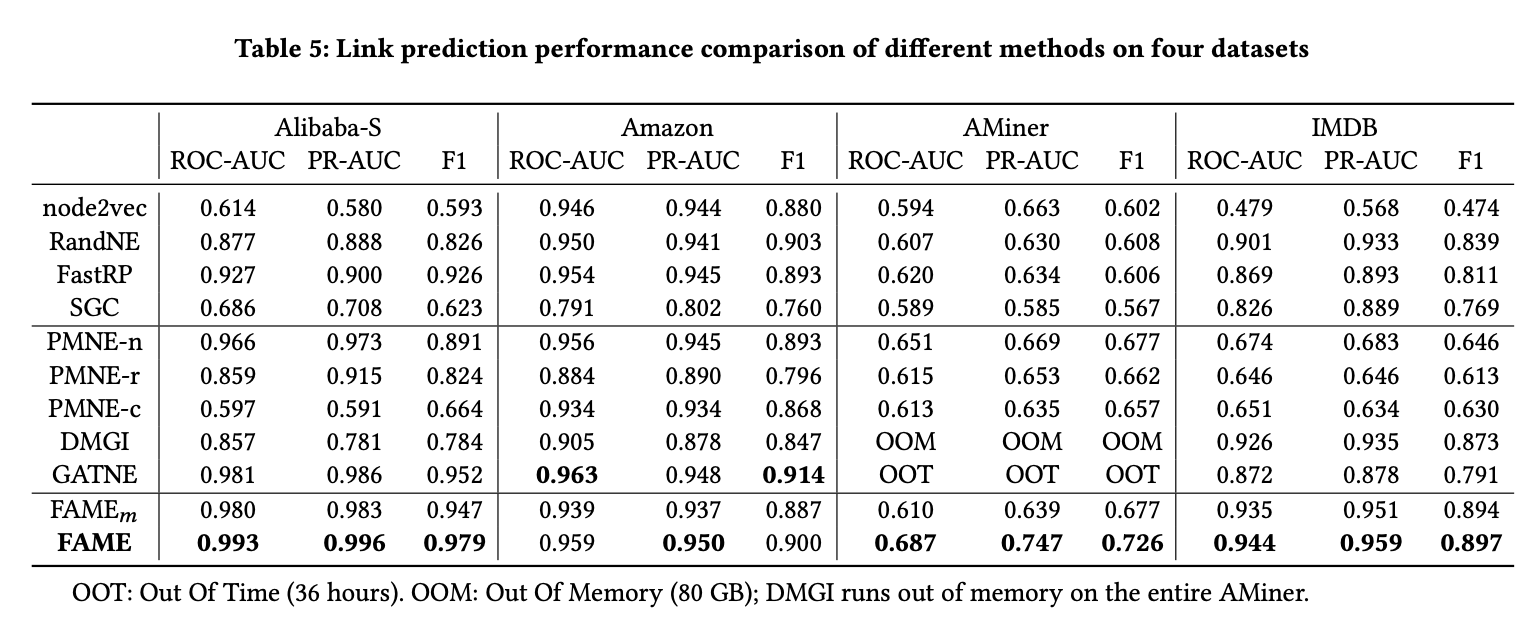
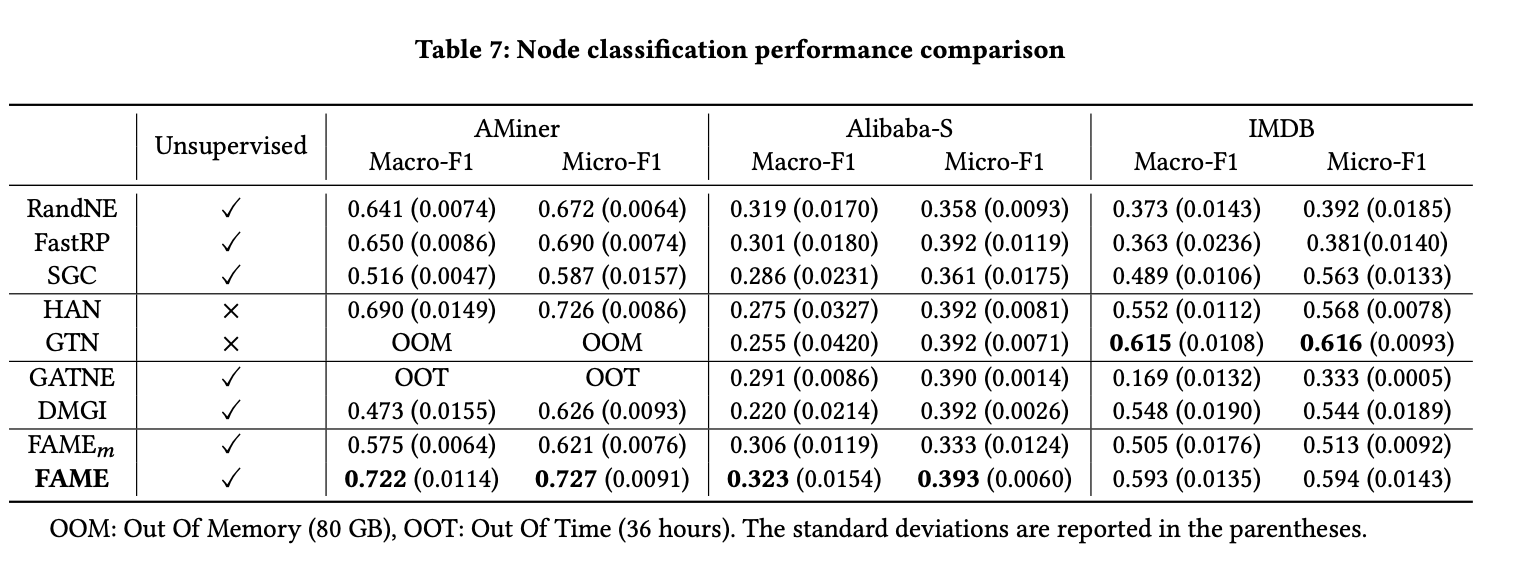
- 效率惊人:在多个真实数据集上,FAME的运行速度比GATNE、GTN等先进的AMHEN模型快了数万倍甚至数十万倍。在其他方法需要数小时甚至因内存溢出(OOM)而失败的大规模数据集上,FAME仅需数秒或数分钟即可完成。
- 效果卓越:在链接预测和节点分类任务上,FAME的性能全面超越了多种基线模型。即使与GATNE这类专门为AMHEN设计的复杂模型相比,FAME在更复杂的网络上也表现出更优的性能,证明了其自动捕捉多重关系结构的能力。
- 可扩展性强:FAME是少数几个能够处理完整、大规模Alibaba数据集(千万级节点,亿级边)的模型之一,并取得了当前最优的性能。
总结#
FAME模型通过一个巧妙的两步框架,成功地解决了大规模属性化多重异构网络(AMHEN)表示学习的核心挑战。
- 它通过谱图变换,自动、优雅地融合了网络的多重关系和高阶结构信息,避免了繁琐的元路径工程。
- 它利用快速稀疏随机投影和矩阵乘法结合律,将计算复杂度显著降低,实现了在超大规模网络上的高效运行。
总而言之,FAME是一个无监督、高效且有效的模型,它不仅在理论上设计精巧,更在实践中展现了处理真实世界复杂大规模网络的巨大潜力,为相关领域的研究和应用提供了强有力的工具。