
Pay Attention to Relations: Multi-embeddings for Attributed Multiplex Networks
在真实世界中,网络结构远比简单的“节点-边”模型复杂。从社交网络中用户间的多种互动(点赞、转发、评论),到生物网络中蛋白质在不同组织内的多样性功能,我们面对的往往是属性化异构多路复兴网络(Attributed Heterogeneous Multiplex Networks, AHMeN)。这类网络包含多种类型的节点和边,且节点自身还带有丰富的属性信息。
传统的图卷积网络(GCN)等模型在处理这种复杂性时常常力不从心,因为它们通常为每个节点只学习一个单一的、全局性的嵌入向量,这难以捕捉节点在不同关系、不同上下文中的多面性。
为了解决这一挑战,来自北卡罗来纳大学夏洛特分校的研究者们提出了 RAHMeN (Relation-aware Embeddings for Attributed Heterogeneous Multiplex Networks),一个新颖的、能够为节点生成“多重嵌入”(Multi-embeddings)的框架。其核心思想是:一个节点的表示不应该是单一的,而应是一组与其参与的各种关系相对应的、互相联系的嵌入向量。这篇博客将严格遵循原论文,为您深入解析RAHMeN的模型架构与设计。
一、核心困境:单一嵌入的局限性#
想象一下,在蛋白质相互作用(PPI)网络中,一个蛋白质可能同时存在于大脑、心脏和肝脏组织中,且在不同组织内扮演的角色(即与其他蛋白质的相互作用关系)截然不同。
- 传统模型:会为这个蛋白质生成一个唯一的嵌入向量,试图将它在所有组织中的信息“平均化”或压缩在一起。这无疑会丢失大量上下文特定的信息。
- RAHMeN的设想:应该为这个蛋白质生成一组嵌入,比如一个“大脑上下文”的嵌入、一个“心脏上下文”的嵌入等。这些嵌入既保留了特定上下文的独特性,又通过某种机制相互关联,共同描绘出该蛋白质的全貌。
RAHMeN正是基于这一设想,通过两大核心组件——关系感知的图卷积和关系语义自注意力机制——来实现这一目标。
二、RAHMeN模型架构深度解析#
RAHMeN的整个流程可以看作一个分层、迭代的过程。在模型的每一层(k-level),它都会执行以下两个关键步骤,如下图所示:
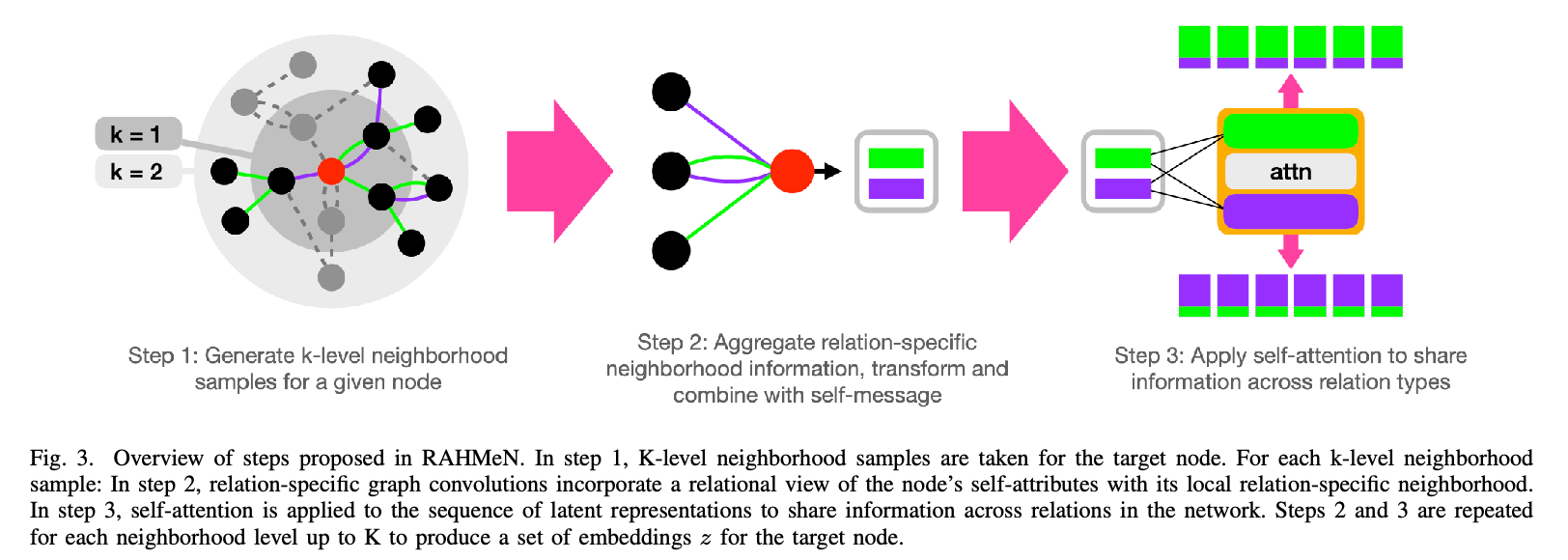
步骤一:关系感知的图卷积 (Relation-Specific Graph Convolution)#
与为整个图应用一个统一卷积核的传统GCN不同,RAHMeN为网络中的**每一种关系(Relation)**都学习了一套专属的图卷积算子。论文将“关系”定义为一个三元组 \(r = (源节点类型, 边类型, 目标节点类型)\)。
在模型的第 \(k\) 层,对于一个目标节点 \(v\) 和一个特定的关系 \(r\),RAHMeN执行以下操作来生成其关系专属的嵌入向量 \(h_{v,r}^k\)。
1. 邻居信息聚合 (Neighbor Aggregation)
首先,模型只关注在关系 \(r\) 下与节点 \(v\) 相连的邻居 \(u ∈ N(v,r)\)。它收集这些邻居在上一层(\(k-1\))的、同样是关系 \(r\) 专属的嵌入 \(h_{u,r}^{k-1}\),并通过一个关系专属的可学习权重矩阵 \(W_{n,r}^k\) 进行变换和聚合(这里采用均值聚合)。
公式(1)如下:
$$ \phi_r^k(\mathcal{N}(v,r)) = \sum_{u \in \mathcal{N}(v,r)} \frac{1}{|\mathcal{N}(v,r)|}\mathbf{W}^k _{n,r} \mathbf{h}_{u,r}^{k-1} $$- \(h_{u,r}^{k-1}\): 邻居节点 \(u\) 在第 \(k-1\) 层、关系 \(r\) 下的嵌入。
- \(W_{n,r}^k\): 第 \(k\) 层专用于聚合关系 \(r\) 下邻居信息的可学习权重矩阵。
2. 自身信息融合与更新 (Self-Representation Combination & Update)
得到聚合后的邻居信息 \(\phi_r^k\),RAHMeN会将其与节点 \(v\) 自身的、经过变换后的信息相结合。这一步同样是关系专属的。
公式(2)如下:
$$ \tilde{\boldsymbol{h}}_{v, r}^k = \sigma \left( \mathbf{W}_{s, r}^k \boldsymbol{h}_{v, r}^{k-1} + \phi_r^k \left( \mathcal{N}(v, r) \right) + \boldsymbol{b}_r^k \right) $$- \(h_{v,r}^{k-1}\): 节点 \(v\) 自身在第 \(k-1\) 层、关系 \(r\) 下的嵌入。
- \(W_{s,r}^k\): 第 \(k\) 层专用于变换节点 \(v\) 自身在关系 \(r\) 下信息的权重矩阵。
- \(σ\): 非线性激活函数,如ELU。
- \(b_r^k\): 偏置项。
通过这一步,RAHMeN为节点 \(v\) 在每一个关系 \(r\) 下都生成了一个新的嵌入 \(h_{v,r}^k\)。至此,我们得到了一组关系专属的、但彼此独立的节点表示。
步骤二:关系语义自注意力机制 (Relational Semantic Self-Attention)#
仅仅得到一组独立的嵌入是不够的。一个节点在“大脑”中的功能可能会受到其在“中枢神经系统”中功能的影响。为了让这些关系专属的嵌入能够“相互沟通”、共享信息,RAHMeN引入了其模型名称的核心——注意力机制。
1. 关系嵌入序列化
首先,将节点 \(v\) 在第 \(k\) 层的所有关系专属嵌入 \(h_{v,r}^k\) 沿着关系维度堆叠起来,形成一个嵌入矩阵 \(H_v^k\),其维度为 \(|R| × d\),其中 \(|R|\) 是关系总数,\(d\) 是嵌入维度。
公式(3)(概念表示):
$$ \tilde{\boldsymbol{h}}_v^k = \text{CONCAT}(\tilde{\boldsymbol{h}}_{v,r}^k | \forall r \in \mathcal{R}) $$2. 计算注意力权重
接下来,模型计算一个 \(|R| × |R|\) 的注意力矩阵 \(a_v^k\)。这个矩阵的第 \((i, j)\) 个元素表示:在为节点 \(v\) 生成其在关系 \(i\) 下的最终嵌入时,应该对关系 \(j\) 下的上下文信息“关注”多少。
公式(4)如下:
$$ \mathbf{a}_v^k = \text{softmax} \left( \mathbf{W}_{\text{rel}}^k ·\tanh(\mathbf{W}_{\text{attn}}^k \tilde{\boldsymbol{h}}_v^k) \right) $$- \(W_{attn}^k\): 一个可学习的变换矩阵,大小为 \(|R| × d × d_a\),用于将每个关系嵌入投影到注意力空间。
- \(W_{rel}^k\): 关键的关系级注意力矩阵(论文中描述为a trainable relation attention matrix),大小为 \(|R| × d_a × |R|\)。它负责计算不同关系之间的相似度或重要性。
- \(tanh\) 和 \(softmax\): 标准的激活和归一化函数。
3. 应用注意力,生成多重嵌入
最后,用计算出的注意力矩阵 \(a_v^k\) 对原始的关系嵌入矩阵 \(H_v^k\) 进行加权,得到一组全新的、融合了所有关系上下文信息的“多重嵌入” \(H_v'^k\)。
公式(5)如下:
$$ \mathbf{h}_v^k = \mathbf{a}_v^k ·[\tilde{\boldsymbol{h}}_{v,r}^k | \forall r \in \mathcal{R}] $$这里的乘法是矩阵乘法 \((|R| × |R|) × (|R| × d)\),结果 \(h_v^k\) 仍然是一个 \(|R| × d\) 的矩阵。\(h_v^k\) 的每一行就是节点 \(v\) 在一个特定关系下的、经过全局信息融合后的新嵌入。这组嵌入就是第 \(k\) 层的最终输出。
经过 \(K\) 层这样的操作,模型最终为每个节点 \(v\) 生成一组 )|R|) 个 \(d\) 维的嵌入向量 \(z_v\),即最终的“多重嵌入”。
三、模型优化#
RAHMeN采用了一种半监督的训练方式。类似于node2vec,它通过在图中进行随机游走来生成节点序列。特别地,它是针对每一种关系 \(r\) 单独进行随机游走,从而捕获特定关系的局部结构。
对于生成的节点序列,模型采用负采样(Negative Sampling)优化的 skip-gram 目标。其目标是最大化在同一游走路径、同一上下文窗口内节点对的共现概率,即最小化负对数似然损失。
公式(10)(损失函数):
$$ E = -\log \sigma(\mathbf{c}_u^T ·\mathbf{z}_{v,r}) - \sum_{i=1}^L \mathbb{E}_{v_i \sim P_{r(u)}}[\log \sigma(-\mathbf{c}_{u}^T \mathbf{z}_{v,r})] $$- \((v,r,u)\): 一个正样本三元组,表示在关系 \(r\) 的上下文中,节点 \(u\) 是 \(v\) 的邻居。
- \(z_{v,r}\): 节点 \(v\) 在关系 \(r\) 下的最终嵌入。
- \(c_u\): 节点 \(u\) 的上下文嵌入。
- \(L\): 负采样的样本数量。
- \(P_{r(u)}\): 噪声分布。
四、RAHMeN的关键优势总结#
- 表达能力强:通过为每个节点生成一组多重嵌入,RAHMeN能够精细地刻画节点在不同关系上下文中的角色和特性,远胜于单一嵌入模型。
- 设计精巧:关系感知的图卷积确保了信息聚合的上下文相关性,而关系语义自注意力机制则实现了跨关系的信息流动和重要性评估。
- 可解释性:模型学到的注意力矩阵 \(a_v\) 提供了极佳的可解释性。例如,在论文的生物网络实验中,模型自动发现“大脑”组织的蛋白质嵌入与“中枢神经系统”和“神经系统”高度相关,这完全符合生物学知识。
- 归纳学习能力:RAHMeN学习的是一套图卷积和注意力变换函数,而不是针对特定节点的嵌入。因此,它可以自然地应用于归纳学习任务,为在训练中未见过的节点生成嵌入。
总而言之,RAHMeN通过其创新的“多重嵌入”和“关系注意力”设计,为理解和建模复杂网络提供了一个强大而富有洞察力的工具,真正做到了“关注关系”(Pay Attention to Relations)。