

PDF: Multimodal Data Enhanced Representation Learning for Knowledge Graphs
1. 引言#
1.1 研究背景#
知识图谱(Knowledge Graph, KG)以结构化的形式存储人类知识,通常以三元组 \((h, r, t)\) 表示,其中 \(h\) 为头实体,\(t\) 为尾实体,\(r\) 为关系。知识表示学习(Representation Learning)旨在将实体和关系映射到低维连续向量空间中,以便于计算和推理。
1.2 问题陈述#
现有的主流方法(如 TransE, TransH, TransR 等)主要基于 结构化知识(Structure Knowledge),即仅利用实体间的关系约束来学习嵌入。这种方法存在两个主要局限:
- 信息利用率低:忽略了实体自身包含的丰富信息(如视觉图像、文本描述)。如图像中不仅包含显式知识(如“椅子有腿”),还包含隐式关联(如“蝴蝶与花高度相关”)。
- 缺乏零样本能力:无法处理未出现在训练集三元组中的实体(Out-of-Knowledge-Base, OOKB),即无法为新实体生成表示。

1.3 论文目标#
为了解决上述问题,论文提出了一种名为 TransAE 的新模型。该模型结合了 多模态自动编码器(Multimodal Autoencoder) 与 TransE 模型,旨在联合学习结构化知识与多模态(视觉和文本)知识,从而提高表示学习的质量,并赋予模型处理未见实体的能力。
2. 核心方法:TransAE 模型#
TransAE 的核心思想是利用自动编码器的中间隐藏层作为实体的嵌入表示(Embedding),并同时约束该表示满足 TransE 的几何结构关系。
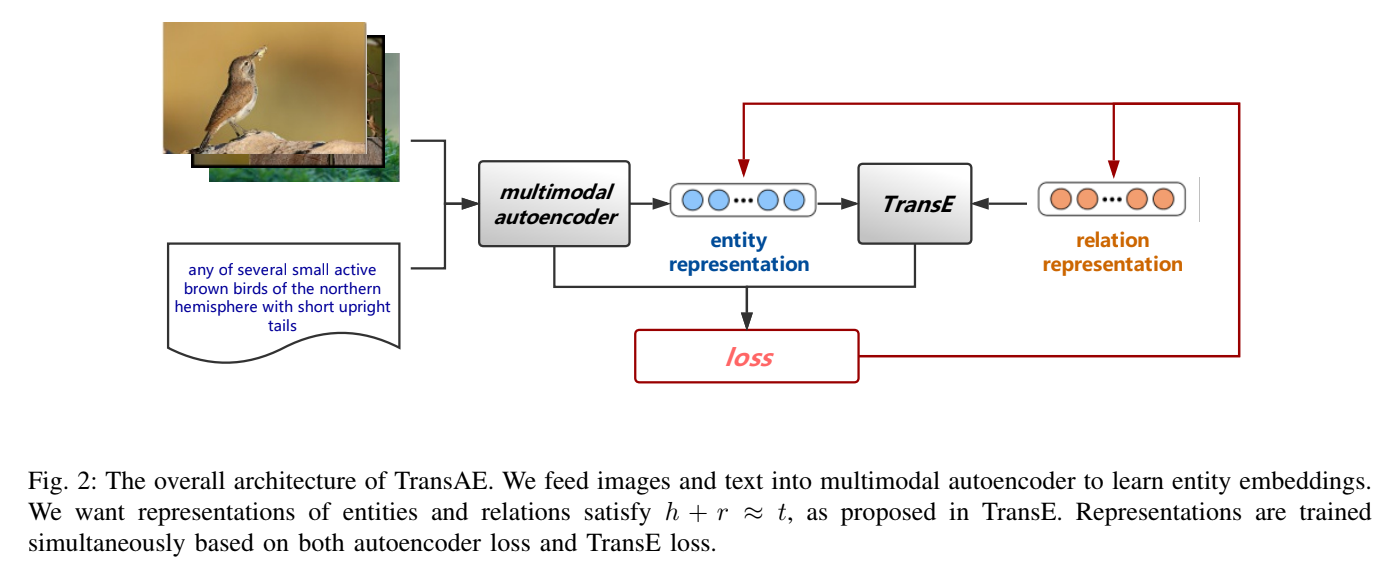
注:模型输入图像和文本特征,通过自动编码器学习实体表示,同时结合 TransE 的损失函数进行联合训练。
2.1 知识提取与预处理 (Knowledge Extraction)#
在输入模型之前,论文首先对多模态数据进行特征提取:
- 视觉知识:使用在 ImageNet 上预训练的 VGG16 Net。提取全连接层的输出作为图像特征向量,维度固定为
4096。 - 文本知识:使用 PV-DM (Doc2Vec) 模型。该模型能综合考虑词序和语义上下文,将变长的文本描述映射为固定长度的向量,实验中设定维度为
100。
2.2 多模态自动编码器 (Multimodal Autoencoder)#
模型的主体是一个前馈神经网络构成的自动编码器,包含编码器(Encoder)和解码器(Decoder)。
编码阶段 (Encoder)#
编码器负责将不同模态的特征融合并压缩为联合表示。
- 输入层:接收图像特征 \(v_i^{(1)}\) 和文本特征 \(v_t^{(1)}\)。
- 第一隐藏层:分别对图像和文本进行非线性映射,降低维度。 $$ v_i^{(2)} = f(W_i^{(1)} \times v_i^{(1)} + b_i^{(1)}) \tag{1} $$ $$ v_t^{(2)} = f(W_t^{(1)} \times v_t^{(1)} + b_t^{(1)}) \tag{2} $$
- 第二隐藏层(瓶颈层):将处理后的图像和文本特征进行拼接(Concatenate),然后映射到联合空间。这一层的输出 \(v^{(3)}\) 即为最终的实体嵌入表示。 $$ v^{(3)} = f(W^{(2)} \times (v_i^{(2)} \oplus v_t^{(2)}) + b^{(2)}) \tag{3} $$ 其中 \(\oplus\) 表示拼接操作,\(v^{(3)}\) 将直接参与 TransE 的计算。
解码阶段 (Decoder)#
解码器结构与编码器对称,旨在从联合表示 \(v^{(3)}\) 重构原始输入,以确保嵌入向量保留了足够的多模态信息。
- 解耦层:将 \(v^{(3)}\) 映射回分离的模态空间。 $$ v_i^{(4)} = f(W_i^{(3)} \times v^{(3)} + b_i^{(3)}) \tag{4} $$ $$ v_t^{(4)} = f(W_t^{(3)} \times v^{(3)} + b_j^{(3)}) \tag{5} $$
- 输出层(重构层):恢复原始维度的特征。 $$ v_i^{(5)} = f(W_i^{(4)} \times v_i^{(4)} + b_i^{(4)}) \tag{6} $$ $$ v_t^{(5)} = f(W_t^{(4)} \times v_t^{(4)} + b_j^{(4)}) \tag{7} $$
其中 \(f\) 为激活函数(本文使用 Sigmoid)。
重构损失 (\(L_a\))#
自动编码器的目标是最小化输入与输出之间的差异:
$$ L_a = \|v_i^{(1)} - v_i^{(5)}\|_2^2 + \|v_t^{(1)} - v_t^{(5)}\|_2^2 \tag{8} $$2.3 结构化知识学习 (TransE 模块)#
论文利用 TransE 的假设指导 \(v^{(3)}\) 的学习。对于三元组 \((h, r, t)\),其嵌入向量应满足 \(h + r \approx t\)。
TransAE 定义结构损失函数 \(L_e'\) 为:
$$ L_e' = \sum_{(h,r,t) \in S} \sum_{(h',r,t') \in S'} \max(0, [\gamma + d(v_h^{(3)}, r, v_t^{(3)}) - d(v_{h'}^{(3)}, r, v_{t'}^{(3)})]) \tag{12} $$- \(v_h^{(3)}, v_t^{(3)}\):由自动编码器生成的头、尾实体表示。
- \(r\):关系嵌入(随机初始化并随模型训练)。
- \(d(\cdot)\):距离度量函数(L1 或 L2 范数)。
- \(\gamma\):间隔超参数(Margin)。
- \(S'\):负采样集合(通过随机替换头或尾实体生成)。
2.4 联合训练目标#
TransAE 的最终目标函数 \(L\) 结合了多模态重构误差、结构化误差以及正则化项:
$$ L = L_a + \beta L_e' + \alpha \Omega(\theta) \tag{13} $$- \(\beta\):平衡结构化知识与多模态知识权重的超参数。
- \(\alpha \Omega(\theta)\):参数正则化项,用于防止过拟合。
这种设计使得 \(v^{(3)}\) 既能通过 \(L_a\) 捕获实体的视觉和文本特征,又能通过 \(L_e'\) 适应知识图谱的结构约束。
3. 实验验证#
3.1 实验设置#
- 数据集:作者构建了 WN9-IMG-TXT 数据集。
- 基于 WN18 的子集 WN9-IMG。
- 规模:6,555 个实体,9 种关系,11,741 个训练三元组。
- 多模态数据:每个实体关联最多 10 张 ImageNet 图片和一段 WordNet 文本定义。
- 基线模型:TransE, TransH, TransR, TransD, RESCAL, HolE, DistMult, ComplEx 以及多模态模型 IKRL, DKRL。
- 参数配置:使用 RMSProp 优化器,学习率 \(\lambda=0.001\),\(\beta=0.4\)。
3.2 链接预测 (Link Prediction)#
该任务预测三元组缺失的头实体或尾实体。评估指标为 Mean Rank (越低越好) 和 Hits@10 (越高越好)。
实验结果(Filter 设置下):
- TransAE:Mean Rank 17,Hits@10 94.2%。
- TransE:Mean Rank 165,Hits@10 87.1%。
- IKRL (Union):Mean Rank 21,Hits@10 93.8%。
结论:TransAE 在各项指标上均优于仅使用结构信息的基线模型,且略优于同类多模态模型 IKRL。这表明融合文本和视觉信息能显著提升实体的表示质量。
3.3 三元组分类 (Triplet Classification)#
该任务判断一个给定的三元组是否正确。
- TransAE 准确率:97.9%。
- 相比 IKRL (96.9%) 和 TransR (95.3%) 均有提升。证明模型能有效区分正负样本。
3.4 零样本学习 (Zero-shot Learning / OOKB)#
这是 TransAE 的核心优势。实验将数据集分为训练集和测试集,测试集中包含训练集中未出现的实体(OOKB实体)。
- 原理:对于 OOKB 实体,虽然没有结构化训练数据(三元组),但可以通过其图像和文本输入到训练好的 Autoencoder 中,直接计算出 \(v^{(3)}\) 作为嵌入表示。
- 结果:
- 实体预测:Mean Rank 约为 290(在 6555 个实体中),这是一个具有实际意义的结果,而传统 TransE 等方法在此任务中无法进行预测(相当于随机猜测)。
- 分类准确率:对于包含 OOKB 实体的三元组,分类准确率达到 90.4%。
3.5 多模态权重分析#
作者调整了超参数 \(w\)(对应公式中的权重比例),分析多模态重构损失 \(L_a\) 对训练的影响。
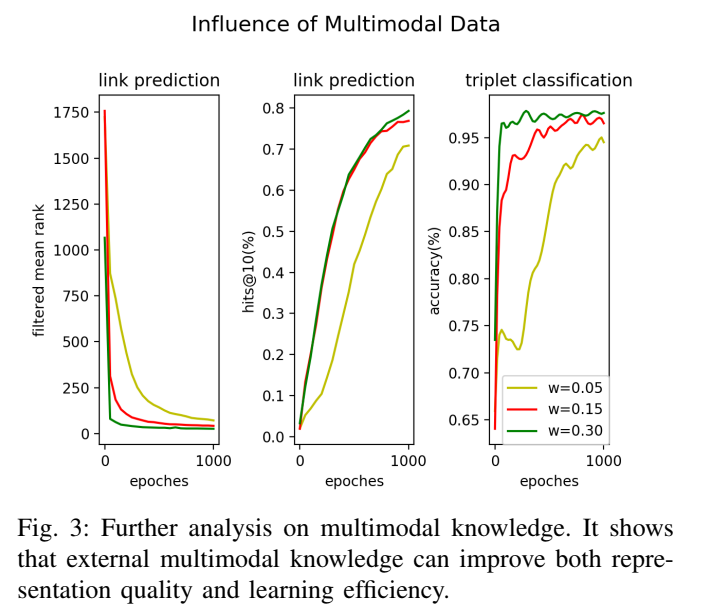
结果显示,随着自动编码器损失权重的增加(即更重视多模态信息),模型的收敛速度变快,且最终性能更好。这证实了引入外部知识有助于提升学习效率和质量。
4. 论文贡献与展望#
4.1 核心贡献总结#
根据论文陈述及实验结果,本研究的实际产出包括:
- 统一的表示框架:TransAE 成功在一个端到端的模型中联合了视觉、文本和结构化知识,通过共享隐藏层实现特征融合。
- 性能提升:在标准 KG 任务(链接预测、分类)上,超越了传统的结构化方法及部分多模态方法。
- 零样本泛化能力:验证了模型利用多模态特征为未知实体(OOKB)生成有效表示的能力,解决了传统 KG 嵌入方法的冷启动问题。
4.2 局限性与未来工作#
作者在结论部分指出了当前工作的潜在改进空间:
- 图文不匹配问题:目前的视觉和文本知识来自不同源,可能存在语义不一致,导致表示学习受损。未来可研究如何匹配和对齐图文信息。
- 噪声处理:提取视觉特征时目前仅关注每个实体的单张或多张图片,忽略了图片中可能包含的复杂关系或其他实体。未来可探索从开放域图像中提取更精细的关系信息。
5. 总结#
TransAE 展示了一条通往更丰富知识表示的路径:事实(Facts)不仅存在于图谱的连边中,也蕴含在实体的多模态描述里。通过将感知(视觉/文本)与认知(关系结构)结合,模型不仅“看”得更准,还能推断未曾“见”过的实体,体现了多模态融合在知识图谱领域的巨大潜力。