
本文介绍了组序列策略优化(GSPO),这是我们为训练大语言模型而开发的稳定、高效且性能优异的强化学习算法。与以往采用token级重要性比率的算法不同,GSPO基于序列似然定义重要性比率,并执行序列级裁剪、奖励和优化。我们证明了GSPO相比GRPO算法实现了卓越的训练效率和性能,显著稳定了专家混合(MoE)强化学习训练,并具有简化强化学习基础设施设计的潜力。GSPO的这些优点为最新的Qwen3模型的显著改进做出了贡献。
1 引言#
强化学习(RL)已成为扩展语言模型的关键范式(OpenAI, 2024; DeepSeek-AI, 2025; Qwen, 2025b;a)。通过大规模强化学习,语言模型发展出处理复杂问题的能力,如竞赛级数学和编程,通过进行更深入和更长的推理过程。
为了成功地通过更大的计算投入来扩展强化学习,最重要的先决条件是保持稳定和鲁棒的训练动态。然而,当前最先进的强化学习算法(以GRPO为代表,Shao等,2024)在训练巨大语言模型时表现出严重的稳定性问题,经常导致灾难性且不可逆的模型崩溃(Qwen, 2025a; MiniMax, 2025)。这种不稳定性阻碍了通过持续强化学习训练来突破语言模型能力边界的努力。
在本文中,我们识别出GRPO的不稳定性源于其算法设计中重要性采样权重的根本误用和失效。这引入了高方差的训练噪声,随着响应长度的增加而逐渐累积,并被裁剪机制进一步放大,最终导致模型崩溃。
为了解决这些核心局限性,我们提出了组序列策略优化(GSPO),这是一种用于训练大语言模型的新型强化学习算法。GSPO的关键创新在于其基于序列似然的理论基础的重要性比率定义(Zheng等,2023),符合重要性采样的基本原理。此外,GSPO将标准化奖励计算为查询的多个响应的优势,确保序列级奖励和优化之间的一致性。
我们的实证评估表明GSPO在训练稳定性、效率和性能方面显著优于GRPO。关键的是,GSPO从根本上解决了大型专家混合(MoE)模型强化学习训练中的稳定性挑战,消除了对复杂稳定化策略的需求,并显示出简化强化学习基础设施的潜力。GSPO的这些优点最终为最新Qwen3模型的卓越性能改进做出了贡献。我们设想GSPO作为一个鲁棒且可扩展的算法基础,将使语言模型的大规模强化学习训练得以持续发展。
2 预备知识#
符号表示 在本文中,由参数 \(θ\) 参数化的自回归语言模型被定义为策略 \(π_θ\)。我们使用 \(x\) 表示查询, \(D\) 表示查询集合。给定查询 \(x\) 的响应 \(y\),其在策略 \(π_θ\) 下的似然表示为 \(\pi_\theta(y|x) = \prod_{t=1}^{|y|} \pi_\theta(y_t|x, y_{\lt t})\),其中 \(|y|\) 表示 \(y\) 中的token数量。查询-响应对 \((x, y)\) 可以由验证器 \(r\) 评分,得到奖励 \(r(x, y) \in [0, 1]\)。
近端策略优化(PPO) 使用从旧策略 \(π_{θ_{old}}\) 生成的样本,PPO(Schulman等,2017)通过裁剪机制将策略更新限制在旧策略的近端区域内。具体来说,PPO采用以下目标进行策略优化(为了简洁起见,我们此后省略KL正则化项,因为它不是本文的重点):
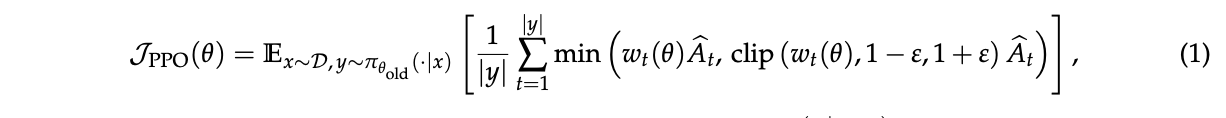
其中token \(y_t\) 的重要性比率定义为 \(w_t(θ) = \frac{π_θ(y_t|x,y_{\lt t})}{π_{θ_{old}}(y_t|x,y_{\lt t})}\),\(y_t\) 的优势 \(\hat{A}_t\) 由另一个价值模型估计,\(ε\) 是重要性比率的裁剪范围。
PPO在实践中的核心挑战在于其严重依赖价值模型。具体来说,价值模型通常与策略模型具有相似的大小,引入了相当大的内存和计算负担。此外,算法有效性取决于其价值估计的可靠性。虽然获得可靠的价值模型本身就具有挑战性,但确保其可扩展到更长的响应和更复杂的任务则面临更大的挑战。
组相对策略优化(GRPO) GRPO(Shao等,2024)通过计算同一查询的一组响应中每个响应的相对优势来绕过对价值模型的需求。具体来说,GRPO优化以下目标:
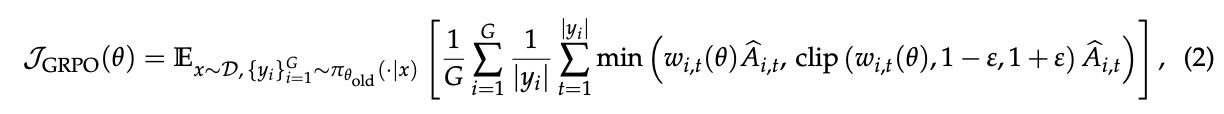
其中 \(G\) 是每个查询 \(x\) 生成的响应数量(即组大小),token \(y_{i,t}\) 的重要性比率 \(w_{i,t}(θ)\) 和优势 \(\hat{A}_{i,t}\) 分别为:
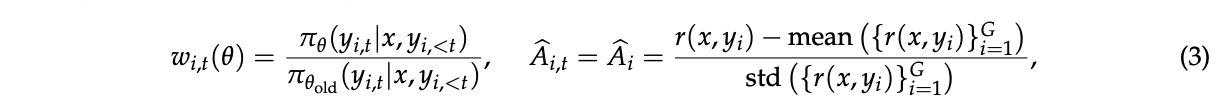
其中 \(y_i\) 中的所有token共享相同的优势 \(\hat{A}_i\)。
3 动机#
模型规模、稀疏性(例如,在专家混合模型中)和响应长度的增长需要大的rollout批次大小来最大化强化学习期间的硬件利用率。为了提高样本效率,标准做法是将大批量rollout数据分割成多个小批次进行梯度更新。这个过程不可避免地引入了离策略学习设置,其中响应 \(y\) 是从旧策略 \(π_{θ_{old}}\) 而不是正在优化的当前策略 \(π_θ\) 中采样的。这也解释了PPO和GRPO中裁剪机制的必要性,它防止过度"离策略"的样本参与梯度估计。
虽然裁剪等机制旨在管理这种离策略差异,但我们在GRPO中识别出一个更根本的问题:其目标是病态的。这个问题在训练长响应任务的大模型时变得特别严重,导致灾难性的模型崩溃。GRPO目标的病态性源于重要性采样权重的误用。重要性采样的原理是通过重新加权从行为分布 \(π_{beh}\) 中抽取的样本来估计目标分布 \(π_{tar}\) 下函数 \(f\) 的期望:
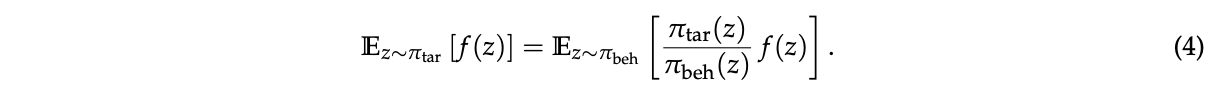
关键的是,这依赖于从行为分布 \(π_{beh}\) 中进行多个样本(\(N ≫ 1\))的平均,使得重要性权重 \(\frac{π_{tar}(z)}{π_{beh}(z)}\) 能够有效地纠正分布不匹配。
相比之下,GRPO在每个token位置 \(t\) 应用重要性权重 \(\frac{π_θ(y_{i,t}|x,y_{i,\lt t})}{π_{θ_{old}}(y_{i,t}|x,y_{i,\lt t})}\)。由于这个权重基于来自每个下一个token分布 \(π_{θ_{old}}(·|x, y_{i,\lt t})\) 的单个样本 \(y_{i,t}\),它无法执行预期的分布纠正作用。相反,它向训练梯度中引入高方差噪声,这种噪声在长序列上累积并被裁剪机制加剧。我们经验性地观察到,这可能导致通常不可逆的模型崩溃。一旦崩溃发生,即使恢复到先前的检查点并仔细调整超参数(例如,裁剪范围)、扩展生成长度或切换强化学习查询,恢复训练也是徒劳的。
上述观察表明GRPO设计中的一个根本问题。token级重要性权重的失败指向一个核心原则:优化目标的单位应该与奖励的单位匹配。由于奖励是授予整个序列的,在token级别应用离策略纠正似乎是有问题的。这促使我们放弃token级目标,探索利用重要性权重并直接在序列级别执行优化。
4 算法#
4.1 GSPO:组序列策略优化#
虽然GRPO中的token级重要性权重 \(\frac{π_θ(y_{i,t}|x,y_{i,\lt t})}{π_{θ_{old}}(y_{i,t}|x,y_{i,\lt t})}\) 是有问题的,但我们观察到当我们在语言生成的背景下应用重要性采样时:
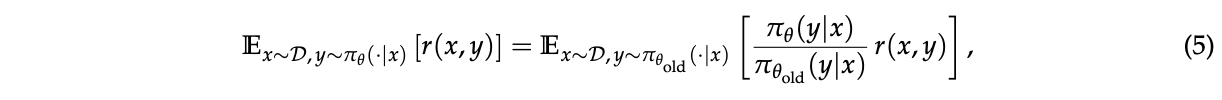
序列级重要性权重 \(\frac{π_θ(y|x)}{π_{θ_{old}}(y|x)}\) 具有明确的理论意义:它反映了从 \(π_{θ_{old}}(·|x)\) 采样的响应 \(y\) 偏离 \(π_θ(·|x)\) 的程度,这自然地与序列级奖励对齐,也可以作为裁剪机制的有意义指标。
基于这个直观的观察,我们提出了组序列策略优化(GSPO)算法。GSPO采用以下序列级优化目标:
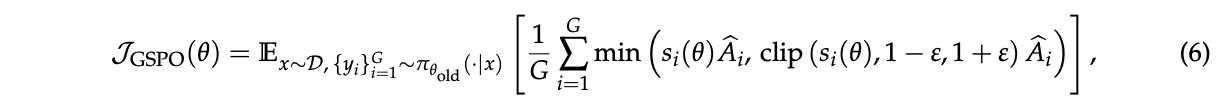
其中我们采用基于组的优势估计:
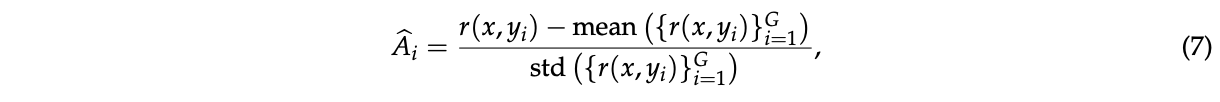
并基于序列似然定义重要性比率 \(s_i(θ)\)(Zheng等,2023):
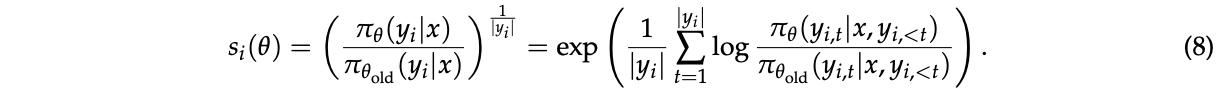
因此,GSPO对整个响应而不是单个token应用裁剪,以从梯度估计中排除过度"离策略"的样本,这与序列级奖励和优化都匹配。注意我们在 \(s_i(θ)\) 中采用长度标准化来减少方差并将 \(s_i(θ)\) 控制在统一的数值范围内。否则,少数token的似然变化可能导致序列级重要性比率的剧烈波动,不同长度响应的重要性比率将需要不同的裁剪范围。我们还注意到,由于重要性比率的不同定义,GSPO和以前算法(例如GRPO)中的裁剪范围通常在数量级上有所不同。
4.2 梯度分析#
我们可以推导GSPO目标的梯度如下(为了简洁起见省略clipping/裁剪):
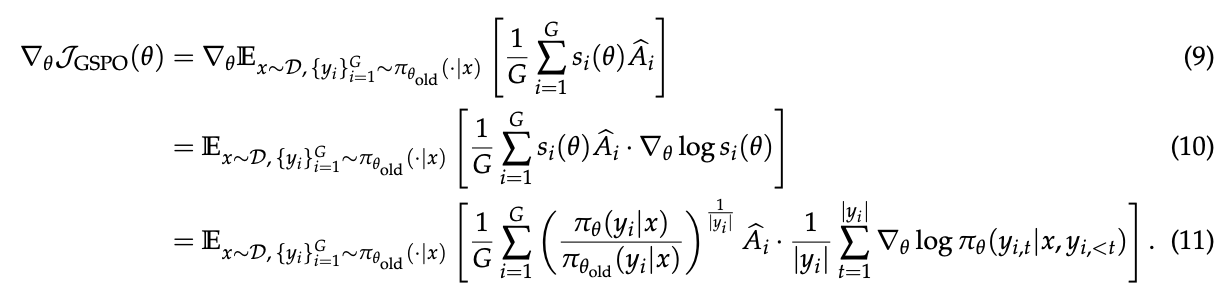
为了比较,GRPO目标的梯度如下(注意 \(\hat{A}_{i,t} = \hat{A}_i\)):
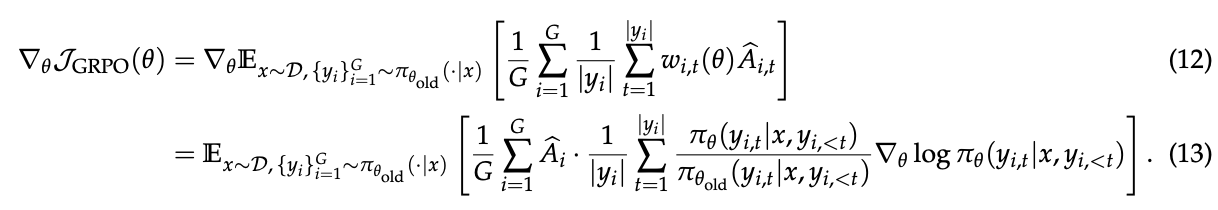
因此,GSPO和GRPO之间的根本区别在于它们如何加权token对数似然的梯度。在GRPO中,token根据其各自的"重要性权重" \(\frac{π_θ(y_{i,t}|x,y_{i,\lt t})}{π_{θ_{old}}(y_{i,t}|x,y_{i,\lt t})}\) 进行加权。然而,这些不等权重可能在 \((0, 1 + ε]\)(对于\(\hat{A}_i > 0\))或 \([1 - ε, +∞)\)(对于 \(\hat{A}_i < 0\))之间变化,它们并非微不足道,随着训练的进行,它们的影响可能累积并导致不可预测的后果。相比之下,GSPO对响应中的所有token进行等权重加权,消除了GRPO的这种不稳定因素。
4.3 GSPO-token:token级目标变体#
在多轮强化学习等场景中,我们可能希望在token级别进行更细粒度的优势调整。为此,我们引入了GSPO的token级目标变体,即GSPO-token,以允许token级优势定制:
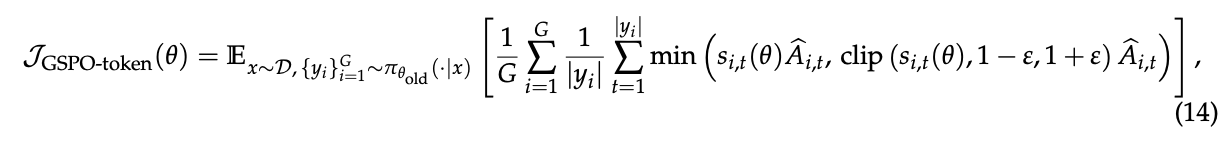
其中
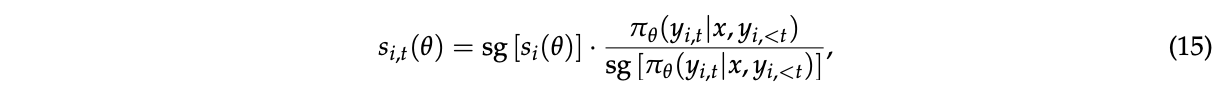
\(\text{sg}[·]\) 表示仅取数值但停止梯度,对应PyTorch中的detach操作。GSPO-token的梯度可以推导为:
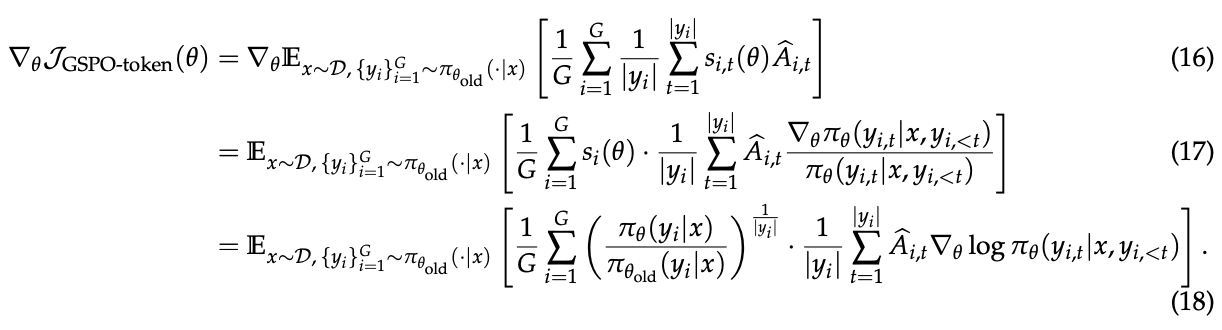
注意项 \(\frac{π_θ(y_{i,t}|x,y_{i,\lt t})}{\text{sg}[π_θ(y_{i,t}|x,y_{i,\lt t})]}\) 的数值为1。因此,比较方程(11)和方程(18),当我们将响应 \(y_i\) 中所有token的优势设置为相同值(即 \(\hat{A}_{i,t} = \hat{A}_i\) )时,GSPO-token在优化目标、裁剪条件和理论梯度方面在数值上与GSPO相同,同时享有按token调整优势的更高灵活性。
5 实验和讨论#
5.1 实证结果#
我们使用从Qwen3-30B-A3B-Base微调的冷启动模型进行实验,并报告训练奖励曲线以及在AIME'24(32次采样的Pass@1)、LiveCodeBench(202410-202502,8次采样的Pass@1)和CodeForces(Elo评级)基准上的模型性能曲线。我们以GRPO算法作为基线,我们已经仔细调优(例如,方程2中的两个裁剪范围)以确保公平比较。注意GRPO需要路由重放训练策略才能使MoE强化学习正常收敛,这将在§5.3中额外讨论,而GSPO已经消除了对这种策略的需求。
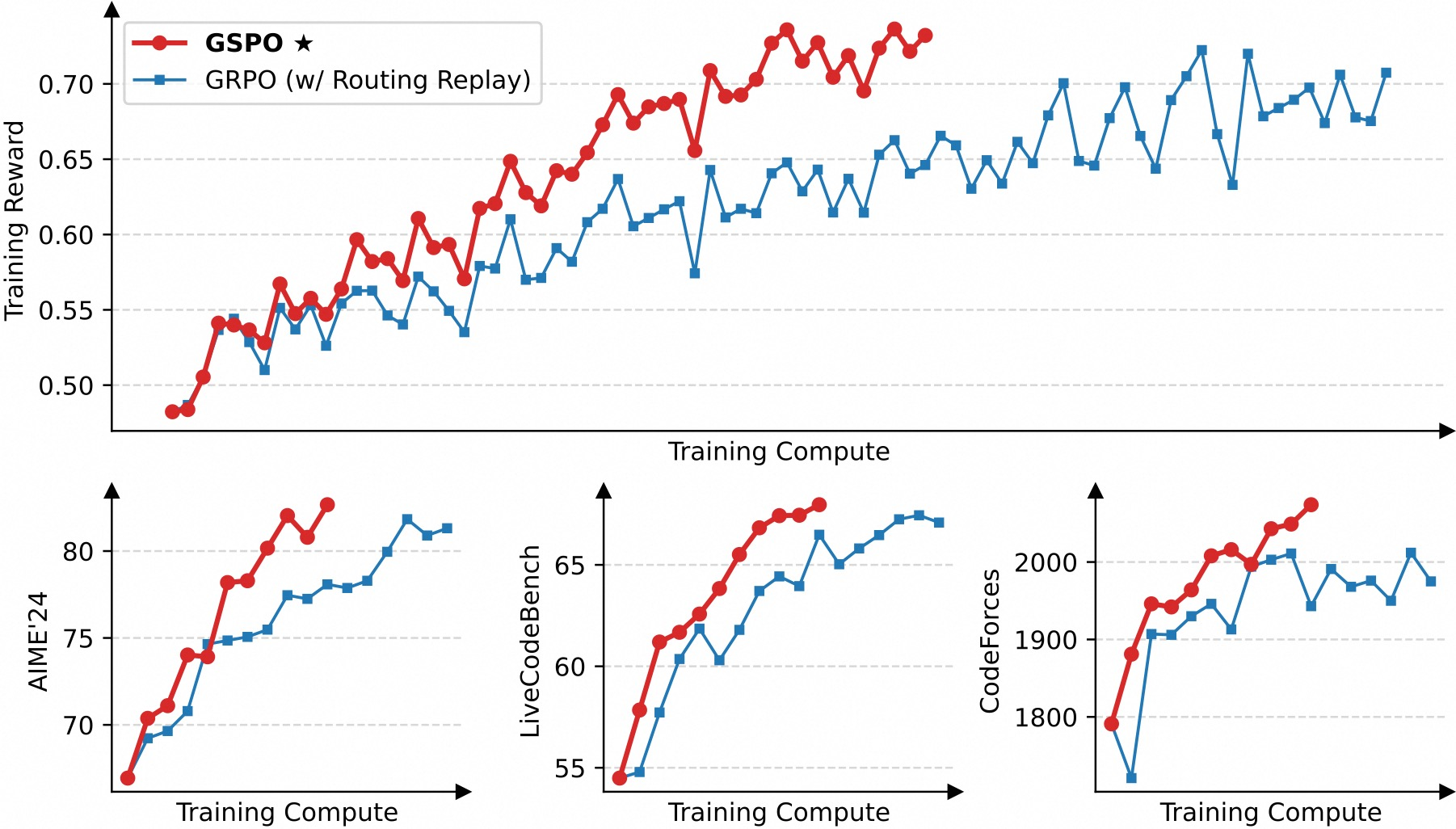
图1显示GSPO的训练始终稳定进行。我们观察到GSPO可以通过增加训练计算、定期更新查询集和扩展生成长度来提供持续的性能改进。此外,GSPO还表现出优于GRPO的训练效率,在相同的训练计算和消耗查询下实现更好的训练准确性和基准性能。最后,我们已成功将GSPO应用于最新Qwen3模型的强化学习训练,有力证明了GSPO在释放大语言模型强化学习扩展能力方面的有效性。
5.2 关于裁剪分数的有趣观察#
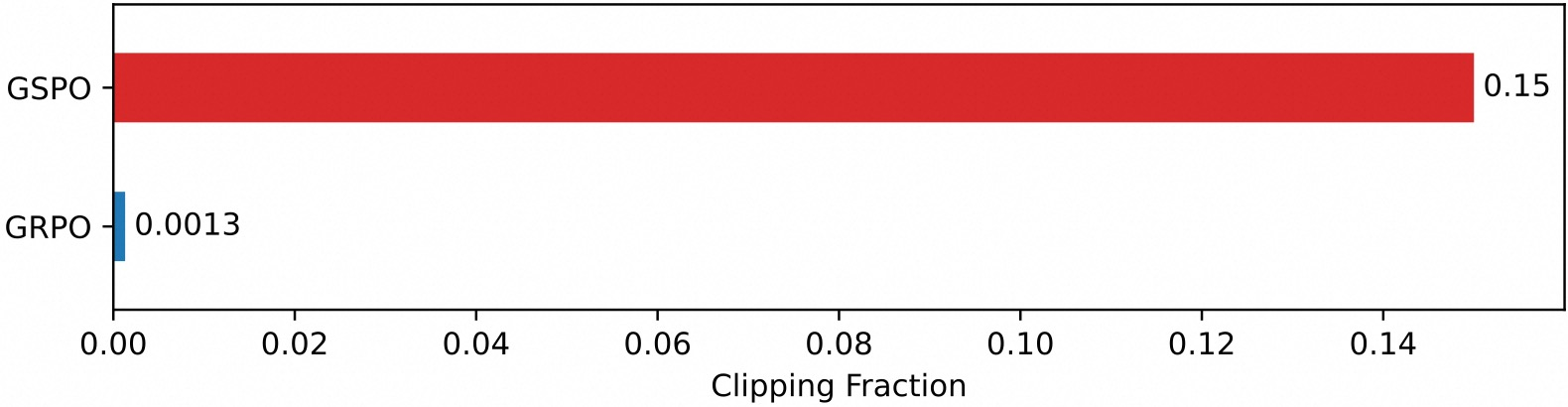
GSPO与GRPO相比的一个关键区别是它裁剪整个响应而不是单个token的做法。特别是,如图2所示,我们观察到GSPO和GRPO之间裁剪token分数有两个数量级的差异(虽然调整裁剪范围不会改变幅度差异)。然而,尽管裁剪了显著更多的token并因此使用更少的token进行训练(或梯度估计),GSPO仍然实现了比GRPO更高的训练效率。这个反直觉的发现——裁剪更大比例的token导致更优的训练效率——进一步表明GRPO的token级梯度估计本质上是嘈杂和低效的样本利用。相比之下,GSPO的序列级方法提供了更可靠和有效的学习信号。
5.3 GSPO对MoE训练的益处#
背景 与密集模型的强化学习训练相比,MoE模型的稀疏激活性质引入了独特的稳定性挑战。特别是,我们发现当采用GRPO算法时,MoE模型的专家激活波动性可能阻止强化学习训练正常收敛。具体来说,在一次或多次梯度更新后,为同一响应激活的专家可能发生显著变化。例如,对于48层的Qwen3-30B-A3B-Base模型,在每次强化学习梯度更新后,对于同一rollout样本,在新策略 \(π_θ\) 下激活的专家中大约有10%与在旧策略 \(π_{θ_{old}}\) 下激活的专家不同。这种现象在更深的MoE模型中变得更加突出,使得token级重要性比率 \(w_{i,t}(θ) = \frac{π_θ(y_{i,t}|x,y_{i,\lt t})}{π_{θ_{old}}(y_{i,t}|x,y_{i,\lt t})}\) 剧烈波动并进一步使其失效,如§3和§4.2中所讨论的,从而阻碍强化学习训练的正常收敛。
我们以前的方法 为了解决这个挑战,我们以前采用了路由重放训练策略。具体来说,我们缓存 \(π_{θ_{old}}\) 中激活的专家,并在计算重要性比率 \(w_{i,t}(θ) = \frac{π_θ(y_{i,t}|x,y_{i,\lt t})}{π_{θ_{old}}(y_{i,t}|x,y_{i,\lt t})}\) 时在 \(π_θ\) 中"重放"这些路由模式。这样,对于每个token \(y_{i,t}\),\(π_θ(y_{i,t}|x, y_{i,\lt t})\) 和 \(π_{θ_{old}}(y_{i,t}|x, y_{i,\lt t})\) 共享相同的激活网络,以便我们可以恢复token级重要性比率的稳定性,并确保在梯度更新间一致激活网络的优化。图3表明路由重放是MoE模型GRPO训练正常收敛的关键技术。
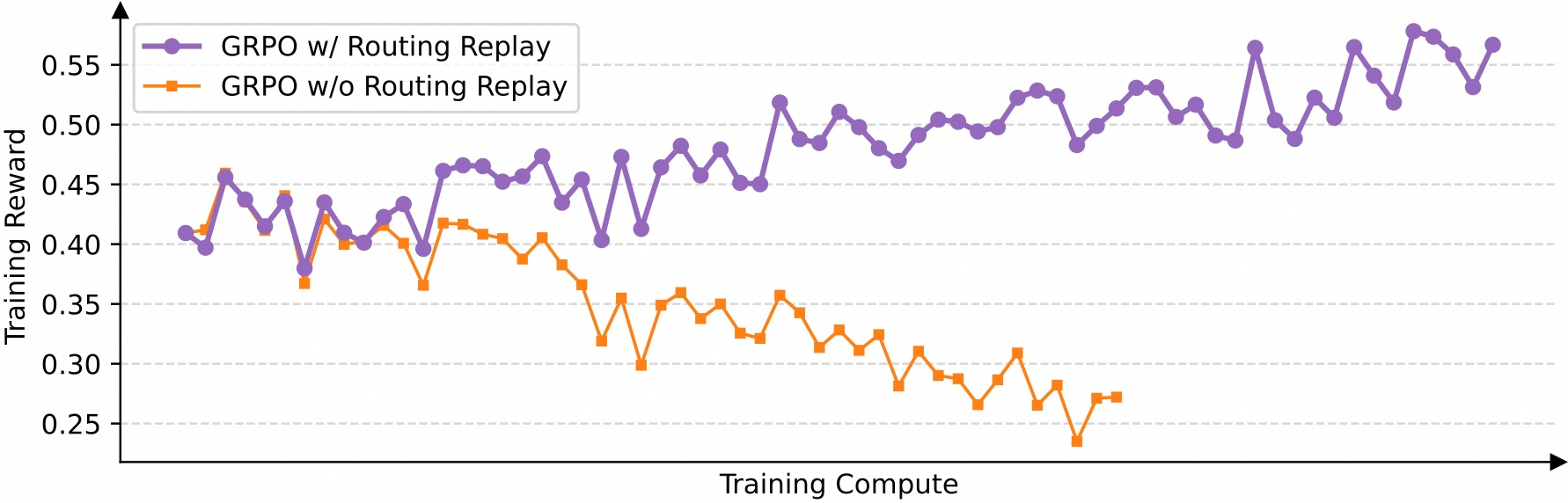
GSPO的益处 虽然路由重放使MoE模型的GRPO训练能够正常收敛,但其重用路由模式的做法产生了额外的内存和通信开销,也可能限制MoE模型的实际容量。相比之下,如图1所示,GSPO消除了对路由重放的依赖,完全能够常规计算重要性比率 \(s_i(θ)\),正常收敛,稳定优化。关键洞察是GSPO只关注序列似然「即 \(\pi_\theta(y_i \mid x)\)」,对单个token似然「即 \(\pi_\theta(y_{i,t} \mid x, y_{i, \lt t})\)」不敏感。由于MoE模型始终保持其语言建模能力,序列似然不会剧烈波动。总之,GSPO从根本上解决了MoE模型中的专家激活波动性问题,消除了对路由重放等复杂变通方法的需求。这不仅简化和稳定了训练过程,还允许模型在没有人为约束的情况下利用其全部容量。
5.4 GSPO对强化学习基础设施的益处#
鉴于训练引擎(例如Megatron)和推理引擎(例如SGLang和vLLM)之间的精度差异,在实践中,我们通常使用训练引擎重新计算采样响应在旧策略 \(π_{θ_{old}}\) 下的似然。然而,GSPO仅使用序列级而不是token级似然进行优化,直观上,前者对精度差异的容忍度要高得多。因此,GSPO使得直接使用推理引擎返回的似然进行优化成为可能,从而避免了使用训练引擎重新计算的需要。这在部分rollout和多轮强化学习等场景以及训练-推理分离框架中特别有益。
6 结论#
我们提出了组序列策略优化(GSPO),这是一种用于训练大语言模型的新型强化学习算法。遵循重要性采样的基本原理,GSPO基于序列似然定义重要性比率,并执行序列级裁剪、奖励和优化。GSPO相比GRPO表现出显著优越的训练稳定性、效率和性能,并对MoE模型的大规模强化学习训练表现出特别的有效性,为最新Qwen3更新中的卓越改进奠定了基础。以GSPO作为可扩展的算法基石,我们将继续扩展强化学习,并期待由此产生的智能基础性进步。