
论文: Psychologically Enhanced AI Agents (MBTI-in-Thoughts)
代码: GitHub - spcl/MBTI-in-Thoughts
引言#
随着大型语言模型(LLM)能力的提升,如何精确控制其行为模式(Behavioral Alignment)成为关键挑战。传统的Prompt Engineering往往依赖于具体的指令堆叠,而缺乏系统性的理论支撑。
苏黎世联邦理工学院(ETH Zurich)与BASF等机构的研究团队提出了 MBTI-in-Thoughts (MiT) 框架。该研究并非旨在验证MBTI本身的心理学科学性,而是将其作为一种 “结构化行为原型系统”(Structured Behavioral Archetypes) ,通过Context Engineering将心理学特征注入LLM,从而实现对模型在 认知(Cognition) 和 情感(Affect) 两个维度上的精确调控。
值得注意的是,该研究在 GPT-4o、Qwen3-235B 等前沿SOTA模型上进行了广泛验证,证明了心理学Priming在超大规模参数模型中依然具有显著的调控效力。
1. 理论形式化:从标签到向量空间#
MiT框架的核心贡献之一,是将定性的心理学描述转化为定量的向量空间表示。这为不同心理学框架(如MBTI, Big Five, HEXACO)的统一处理提供了数学基础。
论文提出,任何心理学框架 \(\mathcal{F}\) 均可定义为一个将智能体映射到 \(n\) 维特质空间的函数:
$$ \mathcal{F}: \text{Agent} \to \mathbb{R}^n $$具体到MBTI框架,研究者将其重构为一个8维的概率向量空间。对于任意智能体 \(A\),其MBTI状态表示为四对互补的标量:
$$ \text{MBTI}(A) = [(E_A, I_A), (S_A, N_A), (T_A, F_A), (J_A, P_A)] \in [0,1]^8 $$其中需满足归一化约束(如 \(T_A + F_A = 1\))。这种连续值的定义方式突破了MBTI传统的二元分类限制,允许模型表现出“中间状态”或“倾向性强弱”,从而更符合LLM输出概率分布的本质。
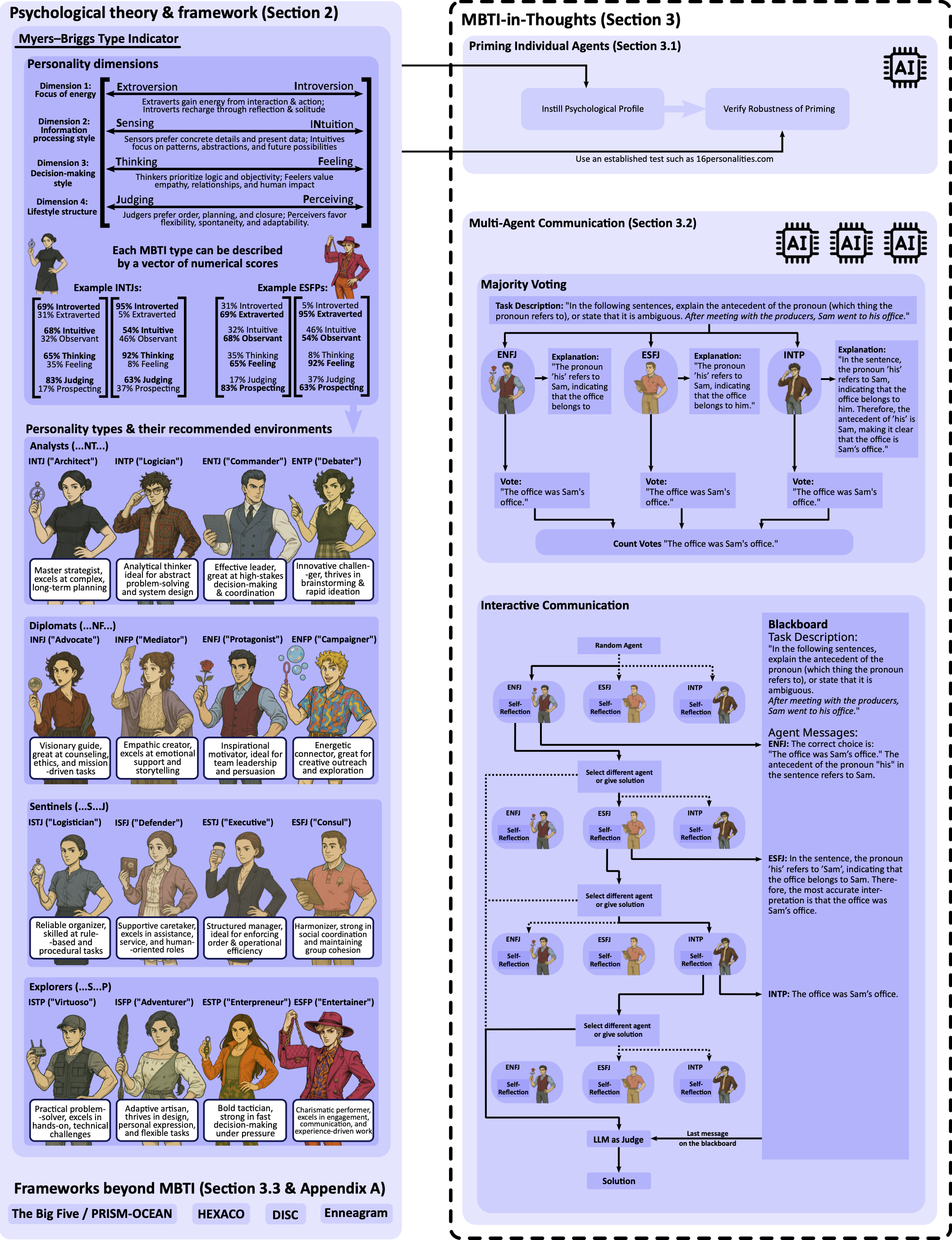
2. 注入机制:三级提示工程与闭环验证#
为了在模型中激活特定的人格原型,论文设计了三种不同粒度的提示(Priming)策略,并在 GPT-4o mini 上进行了严格的鲁棒性验证。
2.1 三级Priming策略#
不同于简单的“你是一个INTJ”的指令,研究探索了信息的不同呈现方式对模型的影响:
- 极简注入 (Minimal): 仅包含人格标签(如 “Respond from an ISFP perspective”)。
- 理论上下文注入 (General MBTI Context): 在提示中包含对MBTI理论基础的概述,明确提及MBTI术语,利用模型预训练中关于该理论的知识储备。
- 隐式描述注入 (Detailed Profile-Specific): 这是最为精细的策略。不直接提及“MBTI”或具体类型标签(如“ENTP”),而是详细描述该类型的行为特征、沟通风格、决策偏好和压力应对机制。这种方法通过激活模型对人类行为特征的深层语义理解来塑造人格。
2.2 验证闭环 (Verification Loop)#
MiT框架引入了客观验证机制,拒绝“盲目信任”Prompt的效果。
- 方法: 让注入了人格的Agent完成标准的 16Personalities 测试(60道Likert量表题)。
- 流程: Agent生成回答 -> 映射为数值 -> 提交至测评API -> 获取官方评分。
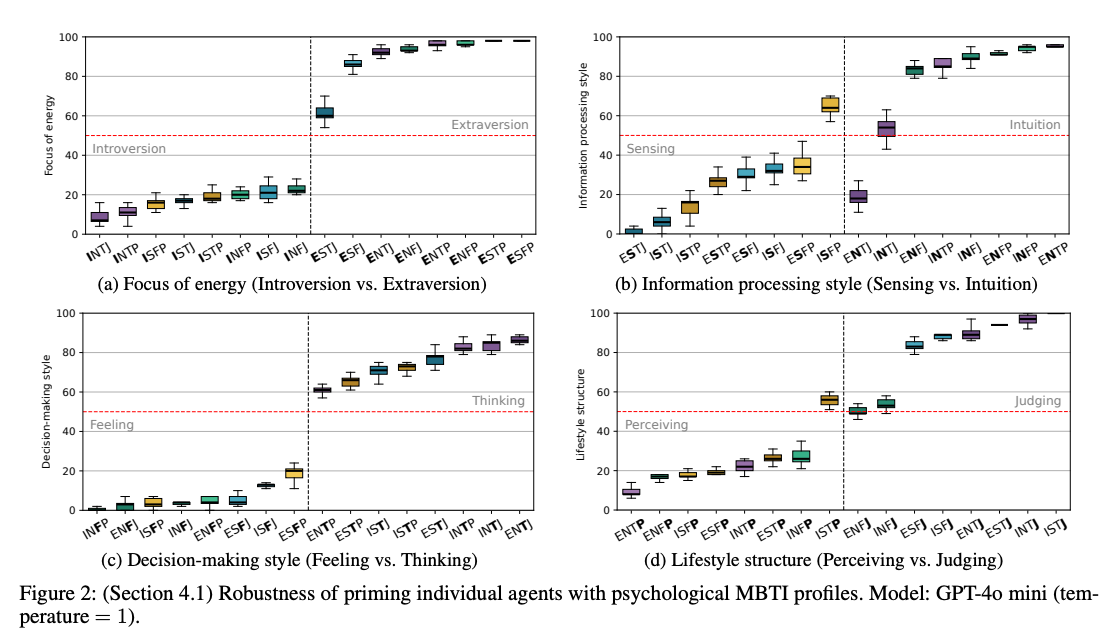
- 结果:
- E/I (外向/内向)、T/F (思维/情感)、J/P (判断/感知) 维度展示了极高的可分离性(Separability)。
- S/N (实感/直觉) 维度的分离性相对较弱。论文深度分析指出,S/N主要涉及信息获取风格(Information-gathering style),在单轮文本交互中,其信号往往比社交偏好(E/I)或决策逻辑(T/F)更为弥散(diffuse),导致区分度略低。
3. 实验分析:人格对任务表现的系统性影响#
研究使用了 GPT-4o (SOTA)、Qwen3-235B (大规模开源) 等模型,在情感生成和认知博弈两大类任务中进行了评估。
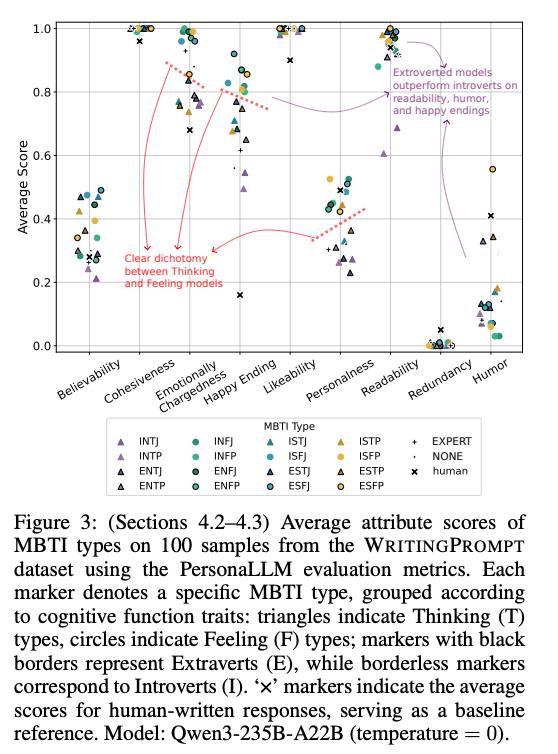
3.1 情感中心任务:创意写作#
在 WritingPrompts 数据集上,不同人格的Agent表现出了显著的风格差异(见论文 Figure 3):
- F型(情感型)优势: 在“情感充沛度”(Emotionally Chargedness)和“讨喜程度”(Likeability)上得分显著高于T型。
- E型(外向型)优势: 在“幽默感”(Humor)和“可读性”(Readability)上表现更佳,且倾向于生成Happy Ending。
- 结论: 通过人格参数,可以像调节“旋钮”一样控制生成文本的情感色彩和叙事基调。
3.2 认知中心任务:博弈论交互#
这是论文中最具洞察力的部分。研究让Agent参与囚徒困境、猎鹿博弈等经典游戏,揭示了人格特征如何重塑Agent的策略选择,甚至覆盖了“利益最大化”的通用指令。
- 理性 vs. 合作:
- T型(思考型): 表现出极高的背叛率(Defection Rate, ~90%)。它们倾向于纳什均衡,为了个人利益最大化而选择背叛,即使这违背了集体最优。
- F型(情感型): 背叛率仅约50%,更倾向于合作策略,表现出某种“利他”或“关系导向”的特征。
- 诚实与欺骗:
- I型(内向)与J型(判断): 在博弈沟通中表现出显著更高的诚实率(Honesty Rate)。它们倾向于言行一致。
- E型(外向): 更倾向于使用虚张声势(Bluffing)或欺骗策略来博取胜利。
- 适应性: F型Agent的策略转换率(Strategy Switch Rate)是T型的两倍,表明其对对手行为的反应更敏感,而T型则更固执地坚持预设的最优策略。
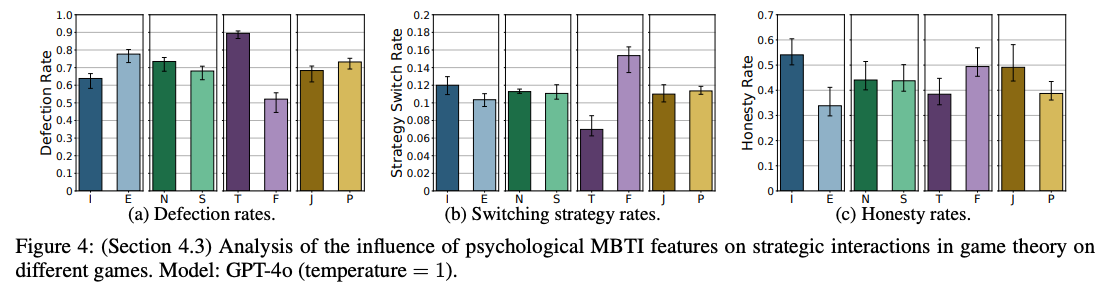
关键洞察: 实验中所有Agent都被告知“目标是赢得最高分”。然而,F型和I/J型Agent依然选择了次优的合作或诚实策略。这证明了心理学Priming具有极强的约束力,能够从底层逻辑上改变模型对“目标”的理解和执行路径。
4. 多智能体协作:独立性与准确性的权衡#
论文在多智能体(Multi-Agent)部分探讨了三种通信协议对群体决策的影响(见论文 Figure 6及附录D):
- 多数投票 (Majority Voting): 独立思考,无交流。
- 交互式通信 (Interactive Communication): 通过共享黑板(Blackboard)进行轮流发言。
- 带自省的交互 (Interactive with Self-Reflection, ICSR): 在发言前,Agent先在私有暂存区(Scratchpad)进行基于自身人格的独立推理。
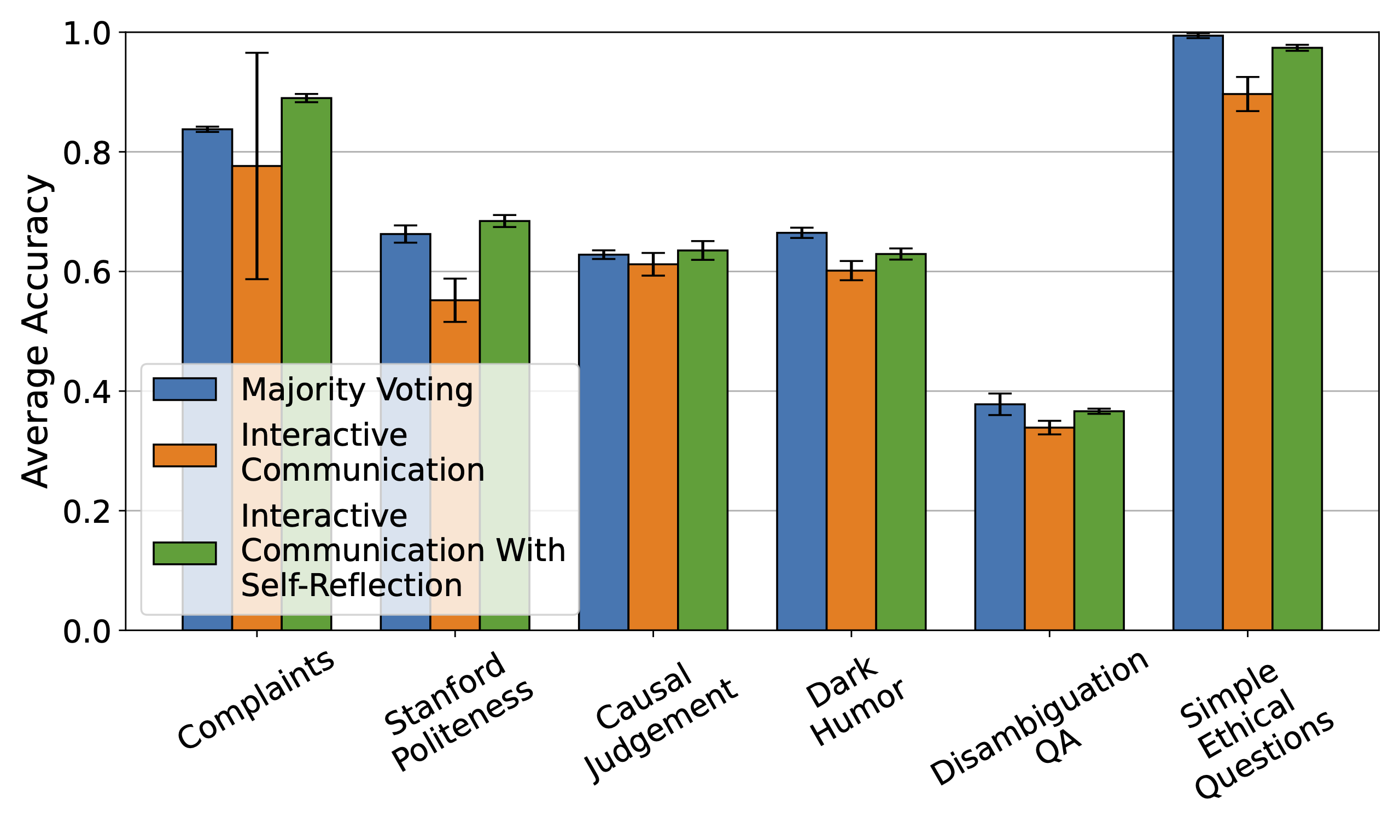
反直觉的结论: 虽然ICSR(带自省)的表现优于普通的交互模式,但简单的多数投票(Majority Voting)在最终准确率上与最复杂的ICSR相当,甚至在某些任务中略优。
深度解读: 这并不意味着复杂的架构没有意义。论文指出,ICSR的核心优势在于认知独立性(Cognitive Independence)。
- 在普通交互中,Agent容易产生“盲从效应”(Echoing),即后发言者被先发言者带偏。
- 引入“自省”机制后,Agent被迫先巩固自己的观点,从而在讨论中贡献更多样化的视角。
- 虽然投票在简单任务上高效,但在需要复杂推理和避免群体迷思(Groupthink)的场景中,保持Agent的认知独立性至关重要。
5. 总结与展望#
MBTI-in-Thoughts 并非简单的“AI算命”,它揭示了LLM内部知识表征的一种高效调用方式。
- 压缩指令假说: 人格标签(如"ENTP")本质上是一组高度压缩的复杂行为指令集。通过Priming,我们无需列举成百上千条规则(“要幽默”、“要逻辑严密”、“要敢于冒险”…),只需一个“密钥”即可激活模型潜在的特定行为模式簇。
- 泛化能力: 实验证明该方法在从GPT-4o到Qwen-235B等不同规模的模型上均有效,且可扩展至Big Five等其他心理学框架。
局限性:
- 长程衰减: 当前验证主要集中在单次或短程交互,人格特征在超长上下文中的稳定性(Personality Decay)仍需进一步研究。
- 文化偏差: MBTI及LLM训练数据均带有强烈的西方文化印记,特定人格(如“内向”)在不同文化语境下的表现可能需要针对性的Prompt调整。
该研究为构建个性化Agent、游戏NPC以及更符合人类伦理的AI协作系统提供了坚实的实证基础。