
1. 背景与痛点#
图检索增强生成(GraphRAG)通过将碎片化知识组织成结构化图谱,显著增强了 LLM 在多跳推理(Multi-hop Reasoning)任务中的表现。然而,现有的 GraphRAG 方案通常面临两个主要瓶颈:
- 构建与检索的割裂 (Isolation): 现有的优化往往孤立地关注图构建(如 OpenIE 的噪声问题)或图检索(如 GNN 匹配),缺乏两者的协同。构建出的图往往不适应检索需求,或者检索器无法充分利用图的结构信息。
- 领域泛化困难 (Domain Shift): 当应用场景从通用领域切换到垂直领域(如医疗、法律)时,预定义的提取规则或检索策略往往失效,导致性能下降。
- 评估的非真实性 (Knowledge Leakage): LLM 可能利用预训练记忆中的知识回答问题,而非依赖检索到的上下文,这掩盖了 RAG 系统的真实检索能力。
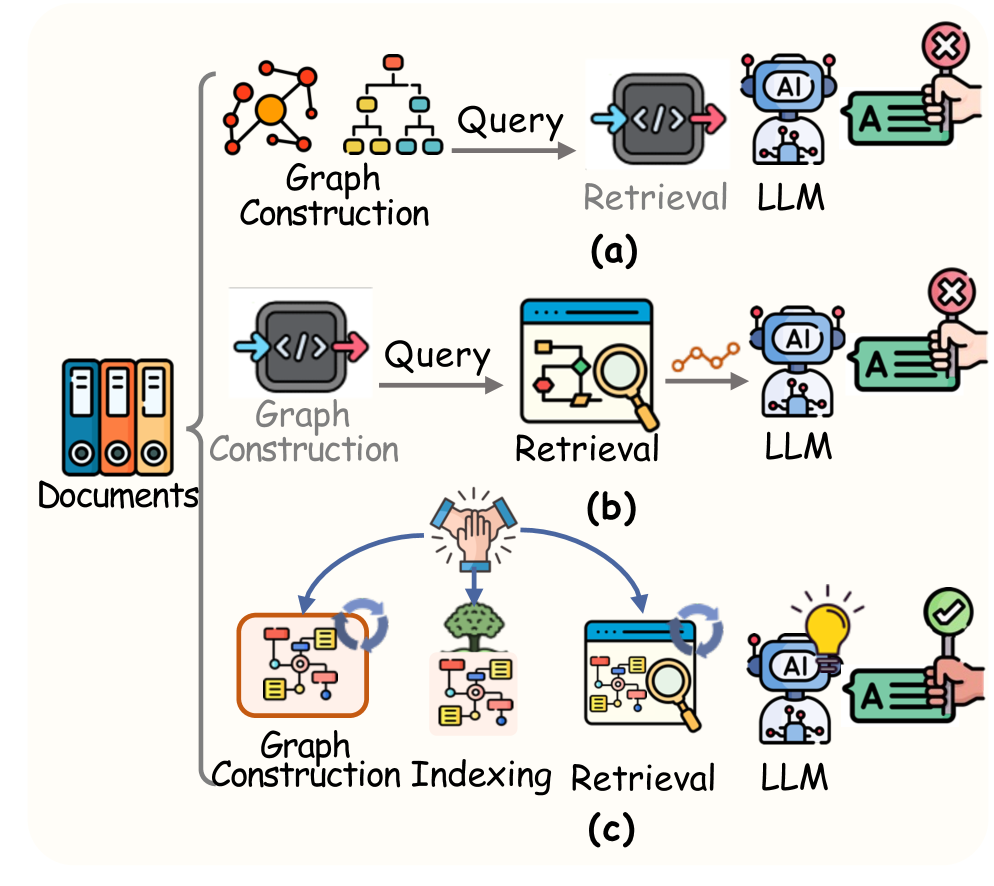
为了解决这些问题,论文提出了 Youtu-GraphRAG,一种垂直统一的智能体范式 (Vertically Unified Agentic Paradigm)。其核心在于通过 图模式 (Graph Schema) 将构建、组织和检索三个阶段紧密耦合,实现了 Token 成本与推理精度的 Pareto 改进。

2. 核心方法论#
Youtu-GraphRAG 的架构包含三个关键组件:Schema 引导的构建、双重感知社区检测、以及基于 Schema 的智能检索。
2.1 Schema 引导的智能体抽取 (Schema-Bounded Agentic Extraction)#
为了解决开放式抽取(OpenIE)带来的噪声问题,该框架引入了“有界自动化”的理念。
定义 Schema: 系统首先定义一个紧凑的种子 Schema \(S\):
$$ S \triangleq \langle S_e, S_r, S_{attr} \rangle $$其中 \(S_e\) 为实体类型,\(S_r\) 为关系类型,\(S_{attr}\) 为属性类型。LLM 被限制在这个笛卡尔积空间 \(S_e \times S_r \times S_{attr}\) 内进行生成,从而保证了图谱的纯净度。
动态演进 (Dynamic Evolution): 为了适应新领域,系统引入了 Schema 演进机制。Agent 会分析文档 \(d\) 中的关系模式,通过以下更新函数自动扩展 Schema:
$$ \Delta S = \langle \Delta S_e, \Delta S_r, \Delta S_{attr} \rangle = \mathbb{I}[ f_{LLM}(d, S) \odot S] \geq \mu $$其中 \(\mu\) 是置信度阈值。这意味着只有当新模式在文档中频繁且一致地出现时,才会被接纳进入 Schema。
2.2 双重感知社区检测 (Dually-Perceived Community Detection)#
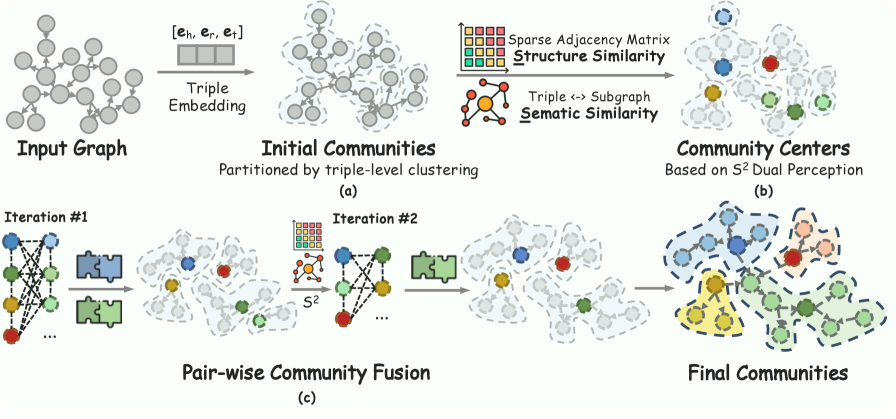
在构建基础图谱后,系统通过社区检测生成层次化知识树。传统的 Leiden 或 Louvain 算法仅基于拓扑结构,忽略了节点的语义信息。Youtu-GraphRAG 提出了一种融合 拓扑结构 (Topology) 与 子图语义 (Subgraph Semantics) 的聚类算法。
实体表示: 首先聚合节点 \(e_i\) 及其一跳邻居 \(\mathcal{N}_i\) 的三元组 Embedding:
$$ \mathbf{e}_i = \frac{1}{|\mathcal{N}_i|} \sum_{(e_i, r, e_j) \in \mathcal{N}_i} [\mathbf{e}_i \| \mathbf{r}_{ij} \| \mathbf{e}_j] $$双重感知评分: 在聚类过程中,定义节点 \(e_i\) 与社区 \(C_m\) 的亲和度评分 \(\phi(e_i, C_m)\):
$$ \phi(e_i, C_m) = \underbrace{S_r(e_i, C_m)}_{\text{relational}} \oplus \lambda \underbrace{S_s(e_i, C_m)}_{\text{semantic}} $$- 拓扑重叠 (\(S_r\)): 计算节点与社区关系的 Jaccard 相似度: $$ S_r(e_i, C_m) = \frac{\|\Psi(e_i) \cap \Psi(C_m)\|_2}{\|\Psi(e_i) \cup \Psi(C_m)\|_2} $$
- 语义相似度 (\(S_s\)): 计算节点 Embedding 与社区质心的余弦相似度。
最终,系统构建了一个深度 \(L=4\) 的知识树 \(\mathcal{K}\):
其中 \(L_4\) 为社区,\(L_3\) 为关键词,\(L_2\) 为实体-关系三元组,\(L_1\) 为属性。
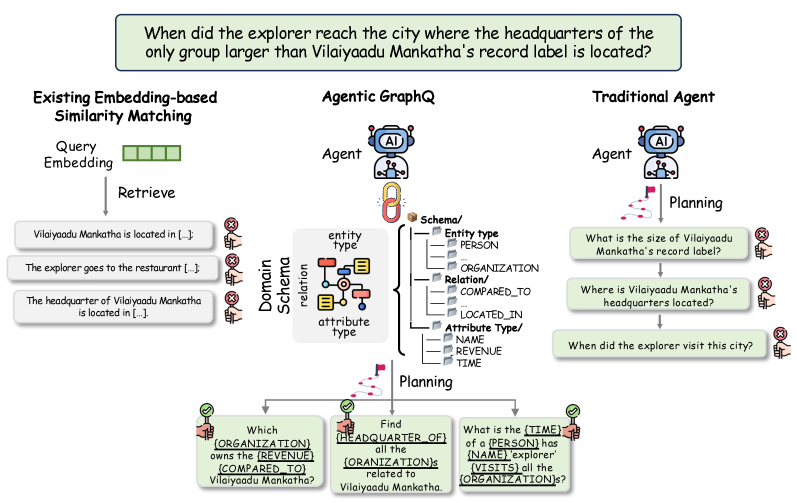
2.3 智能检索器 (Agentic Retriever)#
检索阶段同样利用 Schema 进行复杂问题的降维。
Schema 增强的问题分解: 给定复杂问题 \(q\),Agent 根据 Schema \(S\) 将其分解为原子子查询集 \(Q = \{q_1, q_2, \dots, q_i\}\)。Schema 的存在确保了分解出的子问题中的谓词和实体类型是图谱中存在的,避免了“幻觉式”检索。
迭代推理与反思 (Iterative Reasoning and Reflection): 检索 Agent 被形式化为元组 \(\mathcal{A} = \langle S, \mathcal{H}, f_{LLM} \rangle\),其中 \(\mathcal{H}\) 是历史记忆。Agent 在 Reasoning(推理)和 Reflection(反思)之间交替:
$$ \mathcal{A}^{(t)} = \underbrace{f_{\text{LLM}} \left( q^t \right.}_{\text{Reasoning}} , \underbrace{\left. \mathcal{H}^{(t-1)} \right)}_{\text{Reflection}}, $$多路检索策略: 针对不同的子查询类型,系统并行执行四种检索策略:
- Entity Matching: \(\arg \max \cos(\mathbf{e}, \mathbf{q}_i)\)
- Triple Matching: \(\arg \max \cos((\mathbf{e}_h, \mathbf{r}, \mathbf{e}_t), \mathbf{q}_i)\)
- Community Filtering: \(\arg \max \cos(\mathbf{e}_{C_m}, \mathbf{q}_i)\)
- DFS Path Traversal: 深度优先路径遍历。
3. 评估创新:AnonyRAG 与匿名还原任务#
为了解决 LLM 的数据泄露问题,论文构建了 AnonyRAG 数据集(包含中文和英文版本),并提出了 Anonymity Reversion (匿名还原) 任务。
- 方法: 将数据集中的关键实体(人名、地名)替换为匿名标记(如
[PERSON#277]),迫使 LLM 无法利用预训练知识回答问题,必须完全依赖检索到的上下文线索进行推理。 - 意义: 这种评估方式剥离了 LLM 本身的参数化记忆,能够真实地衡量 RAG 系统的信息检索与逻辑推理能力。
4. 实验结果#
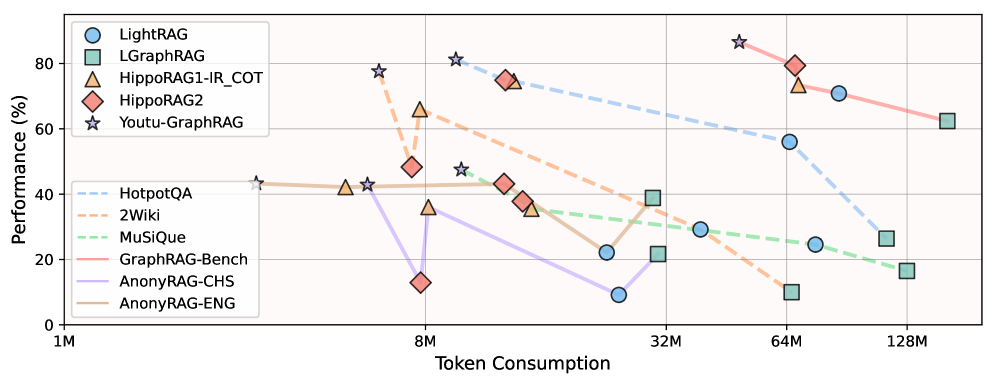
实验在 HotpotQA, 2Wiki, MuSiQue 等 6 个基准数据集上进行。结果显示,Youtu-GraphRAG 实现了显著的性能突破:
- Pareto Frontier 移动: 如图 6 所示,在保持最高准确率的同时,大幅降低了 Token 消耗(最高节省 90.71%)。
- 准确率提升: 相比 SOTA 基线(包括 GraphRAG, HippoRAG 等),准确率提升高达 16.62%。
- 泛化能力: 在“拒绝回答模式”(Reject Mode)下表现优异,证明了其在检索证据不足时能有效抑制幻觉。
5. 总结#
Youtu-GraphRAG 的核心贡献在于将 Schema 这一要素贯穿了 RAG 的全生命周期。它不仅仅是一个静态的约束,更是连接构建 Agent 和检索 Agent 的通用语言(Common Language)。配合双重感知的社区算法,该框架成功地在非结构化文本中建立起了高质量的结构化索引。